Transcription
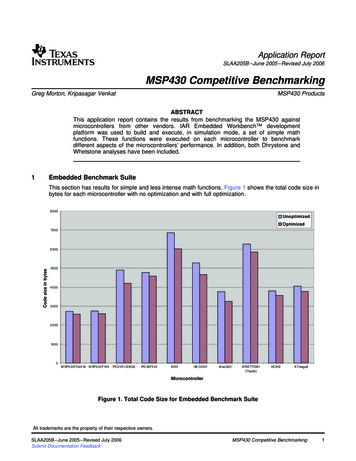
Application ReportSLAA205B – June 2005 – Revised July 2006MSP430 Competitive BenchmarkingGreg Morton, Kripasagar Venkat . MSP430 ProductsABSTRACTThis application report contains the results from benchmarking the MSP430 againstmicrocontrollers from other vendors. IAR Embedded Workbench developmentplatform was used to build and execute, in simulation mode, a set of simple mathfunctions. These functions were executed on each microcontroller to benchmarkdifferent aspects of the microcontrollers' performance. In addition, both Dhrystone andWhetstone analyses have been included.1Embedded Benchmark SuiteThis section has results for simple and less intense math functions. Figure 1 shows the total code size inbytes for each microcontroller with no optimization and with full optimization.8000UnoptimizedOptimized7000Code size in bytes6000500040003000200010000M SP430FG4619 M SP430F149PIC24FJ128GAPIC18F2428051H8/300HM axQ20ARM 7TDM I(Thumb)HCS12ATmega8MicrocontrollerFigure 1. Total Code Size for Embedded Benchmark SuiteAll trademarks are the property of their respective owners.SLAA205B – June 2005 – Revised July 2006Submit Documentation FeedbackMSP430 Competitive Benchmarking1
www.ti.comEmbedded Benchmark SuiteFigure 2 shows the total cycle count for each microcontroller with no optimization and with fulloptimization. Note that some architectures use an internal CPU clock divider. In these architectures, thetotal execution time for the code is the clock divider multiplied by the total instruction cycle count. Thisclock divider is not included in the total cycle count numbers presented here. See Appendix A.1 for moreinformation regarding CPU clock 50000400003000020000100000M SP430FG4619 M SP430F149PIC24FJ128GAPIC18F2428051H8/300HM axQ20ARM 7TDM I(Thumb)HCS12ATmega8MicrocontrollerFigure 2. Total Instruction Cycles for Embedded Benchmark SuiteThe MSP430FG4619 differs in architecture from the MSP430F149 and has the MSP430X CPU. TheMSP430X CPU can address up to 1-MB address range without paging. In addition, the MSP430X CPUhas fewer interrupt overhead cycles and fewer instruction cycles, in some cases, than the MSP430 CPU.The MSP430X CPU is completely backward compatible with the MSP430 CPU. Code size and cyclecount values are shown in Appendix A.2MSP430 Competitive BenchmarkingSLAA205B – June 2005 – Revised July 2006Submit Documentation Feedback
www.ti.comEmbedded Benchmark SuiteTable 1 shows the total code size and the total instruction counts for each microcontroller, normalizedagainst the MSP430FG4619, for the Embedded Benchmark Suite.Table 1. Normalized Results for Embedded Benchmark SuiteMICROCONTROLLERTOTAL CODE SIZETOTAL INSTRUCTION CYCLE COUNTUNOPTIMIZEDFULLY OPTIMIZEDUNOPTIMIZEDFULLY Appendix B includes the code names and a brief description of their functionality used for thisbenchmarking.SLAA205B – June 2005 – Revised July 2006Submit Documentation FeedbackMSP430 Competitive Benchmarking3
www.ti.comMath-Intense Benchmark Suite2Math-Intense Benchmark SuiteIn order to exhibit the performance of each of the microcontrollers under intense math operations, thebenchmarking of a Finite Impulse Response (FIR) filter that requires multiply and accumulate (MAC) isincluded in this report. Also included are the results of the Dhrystone and Whetstone benchmarks. Codesize and cycle count values are shown in Appendix A.Figure 3 shows the code size for each microcontroller, with no optimization and full optimization, for theimplementation of an FIR filter.2500UnoptimizedOptimizedCode size in bytes2000150010005000M SP430FG4619 M SP430F149PIC24FJ128GAPIC18F2428051H8/300HM axQ20ARM 7TDM IHCS12ATmega8MicrocontrollerFigure 3. Code Size For FIR Filter Operation4MSP430 Competitive BenchmarkingSLAA205B – June 2005 – Revised July 2006Submit Documentation Feedback
www.ti.comMath-Intense Benchmark SuiteFigure 4 shows the cycle count for each microcontroller, with no optimization and full optimization, for theimplementation of an FIR filter.1200000U n o p t im iz e dO p t im iz e d1000000Cycles8000006000004000002000000M SP430F G 4619M SP430F 149P IC 2 4 F J 1 2 8 G AP IC 1 8 F 2 4 28051H 8 /3 0 0 HM axQ 20A R M 7T D M IH C S12A T M eg a 8M ic ro c o n tro lle rFigure 4. Cycle Count For FIR Filter OperationTable 2 shows the total code size and the total instruction cycle count for each microcontroller, normalizedagainst the MSP430FG4619, for the FIR filter operation.Table 2. Normalized Results for FIR Filter OperationTOTAL INSTRUCTIONCYCLE COUNTTOTAL CODE SIZEMICROCONTROLLERUNOPTIMIZEDFULLY OPTIMIZEDUNOPTIMIZEDFULLY 5SLAA205B – June 2005 – Revised July 2006Submit Documentation FeedbackMSP430 Competitive Benchmarking5
www.ti.comMath-Intense Benchmark SuiteThe Dhrystone benchmark gauges the performance of a microcontroller in handling pointers, structures,and strings. Figure 5 shows the code size for each microcontroller, with no optimization and fulloptimization, for the implementation of this code.3500UnoptimizedOptimized3000Code size in bytes25002000150010005000M SP430FG4619M SP430F149PIC24FJ128GA8051H8/300HM axQ20ARM 7TDM IHCS12ATmega8MicrocontrollerFigure 5. Code Size In Bytes For Dhrystone Analysis6MSP430 Competitive BenchmarkingSLAA205B – June 2005 – Revised July 2006Submit Documentation Feedback
www.ti.comMath-Intense Benchmark SuiteFigure 6 shows the cycle count for each microcontroller, with no optimization and full optimization, for theDhrystone les5000004000003000002000001000000M SP430FG4619M SP430F149PIC24FJ128GA8051H8/300HM axQ20ARM 7TDM IHCS12ATmega8MicrocontrollerFigure 6. Cycle Count For Dhrystone AnalysisTable 3 shows the total code size and the total instruction cycle count for each microcontroller, normalizedagainst the MSP430FG4619, for the Dhrystone analysis.Table 3. Normalized Results for Dhrystone Analysis(1)TOTAL INSTRUCTIONCYCLE COUNTTOTAL CODE SIZEMICROCONTROLLERUNOPTIMIZEDFULLY OPTIMIZEDUNOPTIMIZEDFULLY 31.031.151.16PIC24FJ128GA1.401.510.560.47PIC18F242 e 30-day trial version of the IAR compiler did not support the memory model required for Dhrystone analysis.SLAA205B – June 2005 – Revised July 2006Submit Documentation FeedbackMSP430 Competitive Benchmarking7
www.ti.comMath-Intense Benchmark SuiteThe Whetstone benchmark attempts to measure the performance of both integer and floating-pointarithmetic in a variety of scientific functions. The code has a mixture of C functions to calculate the sine,cosine, exponent, etc., of fixed-point and floating-point numbers. Figure 7 shows the code size for eachmicrocontroller, with no optimization and full optimization, for the implementation of this code.14000UnoptimizedOptimized12000Code size in bytes1000080006000400020000M SP 430FG4619 M SP 430F149P IC24FJ128GA8051H8/300HM axQ20A RM 7TDM IHCS12A Tmega8MicrocontrollerFigure 7. Code Size In Bytes For Whetstone Analysis8MSP430 Competitive BenchmarkingSLAA205B – June 2005 – Revised July 2006Submit Documentation Feedback
www.ti.comMath-Intense Benchmark SuiteFigure 8 shows the cycle count for each microcontroller, with no optimization and full optimization, for theWhetstone analysis.900000UnoptimizedFully 02000001000000M SP430FG4619M SP430F149PIC24FJ128GA8051H8/300HM axQ20ARM 7TDM IHCS12ATmega8MicrocontrollerFigure 8. Cycle Count For Whetstone AnalysisSLAA205B – June 2005 – Revised July 2006Submit Documentation FeedbackMSP430 Competitive Benchmarking9
www.ti.comMath-Intense Benchmark SuiteTable 4 shows the total code size and the total instruction counts for each microcontroller, normalizedagainst the MSP430FG4619, for the Whetstone analysis.Table 4. Normalized Results for Whetstone Analysis(1)TOTAL INSTRUCTIONCYCLE COUNTTOTAL CODE SIZEMICROCONTROLLERUNOPTIMIZEDFULLY OPTIMIZEDUNOPTIMIZEDFULLY 00.991.031.03PIC24FJ128GA0.740.701.021.01PIC18F242 e 30-day trial version of the IAR compiler did not support the memory model required for Whetstone analysis.Appendix B includes the code and a brief description of functionality used for this benchmarking.10MSP430 Competitive BenchmarkingSLAA205B – June 2005 – Revised July 2006Submit Documentation Feedback
www.ti.comAppendix AAppendix A Background InformationThis appendix includes the actual values for all of the benchmarking discussed in this report.A.1Processor Clock vs Instruction Cycle Clock ConsiderationsMCU architectures have different associations between the processor input clock frequency and the actualinstruction cycle clock frequency. Ideally, one processor clock cycle fed into the CPU would result in oneinstruction being executed. However, in some cases, an additional CPU internal clock divider is used(Table 5). Then, multiple processor clock cycles are necessary to execute a single instruction. This isimportant to consider when determining the system clock frequency that is needed to achieve a giventask. Note that higher clock frequencies generally also lead to a higher power consumption due toincreased CMOS logic switching losses.Table A-1. Table 5. CPU Clock Divider(1)SLAA205B – June 2005 – Revised July 2006Submit Documentation FeedbackMicrocontrollerCPU Clock DividerMSP430FG46191MSP430F1491Microchip PIC24FJ128GA2Microchip PIC18F2424Generic 80511.12 (1)Renesas H8/300H2MaxQ201ARM7TDMI1Freescale HCS122Atmel ATmega818051 architectures typically use a divider of 12. However, someimproved architectures can execute a subset of instructions in aslittle as one clock cycle per instruction.MSP430 Competitive Benchmarking11
www.ti.comCompiler Information And Detailed ResultsA.2Compiler Information And Detailed ResultsThe C compiler bundled with IAR Embedded Workbench Integrated Development Environment (IDE) wasused to build the benchmarking applications. Evaluation copies of the IDE were obtained for eachmicrocontroller from IAR Systems’ web site located at http://www.iar.com. Table A-2 lists the C compilerversion used to build the benchmarking applications for each microcontroller.All applications were built with compiler optimization set to “none” and to “full”. This was done to utilize thecompiler’s ability to build efficient code, which has had a great impact on the results.Table A-2. C Compiler Versions(1)MicrocontrollerIAR C Compiler VersionMSP430FG46193.41AMSP430F1493.41AMicrochip PIC24FJ128GA2.02 (1)Microchip PIC18F2423.10AGeneric 80517.20CRenesas H8/300H1.53IMaxQ201.13CARM7TDMI4.31AFreescale HCS123.10AAtmel ATmega84.12AFor this device, the current Microchip MPLAB C30 compiler wasused. An IAR compiler for the PIC24x was not available at the timeof publishing this application note.The following pages include the actual values for all of the benchmarking discussed in this report.Table A-3 and Table A-4 show the code size in bytes for each of the microcontrollers for every mathoperation without optimization and with full optimization, respectively.12MSP430 Competitive BenchmarkingSLAA205B – June 2005 – Revised July 2006Submit Documentation Feedback
www.ti.comCompiler Information And Detailed ResultsTable A-3. Code Size In Bytes Without Optimization For Simple Math 88-Bit Math236232345174266400326684951528-Bit Matrix1201264503684994923484162173948-Bit Switch22020048623830549820053219737816-Bit Math17617233326647839824068410721016-Bit Matrix13616655883469357246043230153216-Bit Switch22019848034251953418653221542432-Bit Math2722684624861050646316644324352Floating-Point Math1134113212661322234611761200186820821096Matrix MSP430FG4619MSP430F149PIC24FJ128GAPIC18F242 (1)8051H8/300HMaxQ20ARM7TDMIHCS12ATmega88-Bit Math214210297170233344230636831348-Bit Matrix1061063663243984122523921883548-Bit Switch21819839320830544419245216235016-Bit Math1621582852864523522046367619816-Bit Matrix11013046569250448232839626243416-Bit Switch21819639028249347818445217438232-Bit Math258254375542909574288620323342Floating-Point Math1122112011941400219011041172183220821088Table A-4. Code Size In Bytes With Full Optimization For Simple Math Operations(1)Matrix 584259241914580602046723248584435693772For some functions, the 30-day trial version of the IAR compiler produced larger code sizes with full optimization than it did with no optimization.SLAA205B – June 2005 – Revised July 2006Submit Documentation FeedbackMSP430 Competitive Benchmarking13
www.ti.comCompiler Information And Detailed ResultsTable A-5 and Table A-6 show the cycle count for each of the microcontrollers for each math operation without optimization and with fulloptimization, respectively.Table A-5. Cycle Count Without Optimization For Simple Math 4FJ128GAPIC18F242 (1)8051H8/300HMaxQ20ARM7TDMIHCS128-Bit Math25026110714121224017587971348-Bit mega88-Bit Switch33327649112964251513916-Bit Math22323310833254225420110210828816-Bit 6-Bit Switch323174873141023551544532-Bit Math56958956412593854520440109267750Floating-Point Math77179578910493339154864420555081663Matrix 12962723365The 30-day trial version of IAR compiler for some functions did produce larger numbers with full optimization, as compared to no optimization.Table A-6. Cycle Count With Full Optimization For Simple Math ga88-Bit Math2332437513617615213064681108-Bit Matrix87510091051219325904362114047515599848-Bit Switch32316149112623820463816-Bit Math210219733395261721837960266148816-Bit Matrix81194511156461429447461508475207316-Bit Switch31306087318663420414432-Bit Math5565755101284262238842597235731Floating-Point Math76278674110852127141662918754701654Matrix 711MSP430 Competitive BenchmarkingSLAA205B – June 2005 – Revised July 2006Submit Documentation Feedback
www.ti.comCompiler Information And Detailed ResultsTable A-7 shows the code size in bytes and cycle count and for each of the microcontrollers for every math operation without optimization and withfull optimization.Table A-7. FIR, Dhrystone, and Whetstone Code Size and Cycle CountsFIR FILTER (1)MCU(1)CODE SIZEDHRYSTONECYCLESCODE SIZEWHETSTONECYCLESCODE 4694274586270991The FIR filter code has been modified for correct operation from the previous version which lacked the MAC operations.SLAA205B – June 2005 – Revised July 2006Submit Documentation FeedbackMSP430 Competitive Benchmarking15
www.ti.comAppendix BAppendix B Benchmarking ApplicationsB.1Benchmarking ApplicationsIn order to benchmark various aspects of a microcontroller’s performance, the following set of simpleapplications was executed in simulation mode for each microcontroller.8-bit math.c — source file containing three math functions. One function performs addition of two 8-bitnumbers, one performs multiplication, and one performs division. The “main()” function calls each ofthese functions.16-bit math.c — source file containing three math functions. One function performs addition of two16-bit numbers, one performs multiplication, and one performs division. The “main()” function callseach of these functions.32-bit math.c — source file containing three math functions. One function performs addition of two32-bit numbers, one performs multiplication, and one performs division. The “main()” function callseach of these functions.floating point math.c — source file containing three math functions. One function performs addition oftwo floating-point numbers, one performs multiplication, and one performs division. The “main()”function calls each of these functions.8-bit switch case.c — source file with one function containing a switch statement having 16 cases. An8-bit value is used to select a particular case. The “main()” function calls the “switch” function withan input parameter selecting the last case.16-bit switch case.c — source file with one function containing a switch statement having 16 cases. A16-bit value is used to select a particular case. The “main()” function calls the “switch” function withan input parameter selecting the last case.8-bit 2-dim matrix.c — source file containing 3 two-dimensional arrays containing 8-bit values—one ofwhich is initialized. The “main()” function copies values from array 1 to array 2, then from array 2 toarray 3.16-bit 2-dim matrix.c — source file containing 3 two-dimensional arrays containing 16-bit values—oneof which is initialized. The “main()” function copies values from array 1 to array 2, then from array 2to array 3.matrix multiplication.c — source file containing code, which multiplies a 3 4 matrix by a 4 5 matrix.fir filter.c — source file containing code that calculates the output from a 17-coefficient tap filter usingsimulated ADC input data.dhry.c — source file containing code, which does the Dhrystone analysis.whet.c — source file containing code, which does the Whetstone analysis.16MSP430 Competitive BenchmarkingSLAA205B – June 2005 – Revised July 2006Submit Documentation Feedback
www.ti.comBenchmarking Application Source CodeB.2Benchmarking Application Source CodeThe following are the C source-code files for the benchmarking applications used in this document.8-bit **************************************Name: 8-bit Math*Purpose : Benchmark 8-bit math ****************************************/typedef unsigned char UInt8;UInt8 add(UInt8 a, UInt8 b){return (a b);}UInt8 mul(UInt8 a, UInt8 b){return (a * b);}UInt8 div(UInt8 a, UInt8 b){return (a / b);}void main(void){volatile UInt8 lt[3]return; 12;3;add(result[0], result[1]);mul(result[0], result[2]);div(result[1], result[2]);}SLAA205B – June 2005 – Revised July 2006Submit Documentation FeedbackMSP430 Competitive Benchmarking17
www.ti.comBenchmarking Application Source Code8-bit 2-dim ****************************************Name: 8-bit 2-dim Matrix*Purpose : Benchmark copying 8-bit *************************************/typedef unsigned char UInt8;const UInt8 m1[16][4] x12}void main (void){int i, j;volatile UInt8 m2[16][4], m3[16][4];for(i 0; i{for(j 0; j{m2[i][j]m3[i][j]}}return; 16; i ) 4; j ) m1[i][j]; m2[i][j];}18MSP430 Competitive BenchmarkingSLAA205B – June 2005 – Revised July 2006Submit Documentation Feedback
www.ti.comBenchmarking Application Source Code8-bit Switch **************************************Name: 8-bit Switch Case*Purpose : Benchmark accessing switch statement using 8-bit ************************************/typedef unsigned char UInt8;UInt8 switch case(UInt8 a){UInt8 output;switch (a){case 0x01:output break;case 0x02:output break;case 0x03:output break;case 0x04:output break;case 0x05:output break;case 0x06:output break;case 0x07:output break;case 0x08:output break;case 0x09:output break;case 0x0a:output break;case 0x0b:output break;case 0x0c:output ;0x0a;0x0b;0x0c;case 0x0d:output 0x0d;break;case 0x0e:output 0x0e;break;case 0x0f:output 0x0f;break;case 0x10:output 0x10;break;} /* end switch*/SLAA205B – June 2005 – Revised July 2006Submit Documentation FeedbackMSP430 Competitive Benchmarking19
www.ti.comBenchmarking Application Source Codereturn (output);}void main(void){volatile UInt8 result;result switch case(0x10);return;}20MSP430 Competitive BenchmarkingSLAA205B – June 2005 – Revised July 2006Submit Documentation Feedback
www.ti.comBenchmarking Application Source Code16-bit **************************************Name: 16-bit Math*Purpose : Benchmark 16-bit math ****************************************/typedef unsigned short UInt16;UInt16 add(UInt16 a, UInt16 b){return (a b);}UInt16 mul(UInt16 a, UInt16 b){return (a * b);}UInt16 div(UInt16 a, UInt16 b){return (a / b);}void main(void){volatile UInt16 lt[3]return; 231;12;add(result[0], result[1]);mul(result[0], result[2]);div(result[1], result[2]);}SLAA205B – June 2005 – Revised July 2006Submit Documentation FeedbackMSP430 Competitive Benchmarking21
www.ti.comBenchmarking Application Source Code16-bit 2-dim ****************************************Name: 16-bit 2-dim Matrix*Purpose : Benchmark copying 16-bit *************************************/typedef unsigned short UInt16;const UInt16 m1[16][4] ,0x3456},0x9012},0x5678},0x1234}void main(void){int i, j;volatile UInt16 m2[16][4], m3[16][4];for(i 0; i{for(j 0;{m2[i][j]m3[i][j]}}return; 16; i )j 4; j ) m1[i][j]; m2[i][j];}22MSP430 Competitive BenchmarkingSLAA205B – June 2005 – Revised July 2006Submit Documentation Feedback
www.ti.comBenchmarking Application Source Code16-bit Switch **************************************Name: 16-bit Switch Case*Purpose : Benchmark accessing switch statement using 16-bit ************************************/typedef unsigned short UInt16;UInt16 switch case(UInt16 a){UInt16 output;switch (a){case 0x0001:output 0x0001;break;case 0x0002:output 0x0002;break;case 0x0003:output 0x0003;break;case 0x0004:output 0x0004;break;case 0x0005:output 0x0005;break;case 0x0006:output 0x0006;break;case 0x0007:output 0x0007;break;case 0x0008:output 0x0008;break;case 0x0009:output 0x0009;break;case 0x000a:output 0x000a;break;case 0x000b:output 0x000b;break;case 0x000c:output 0x000c;break;case 0x000d:output 0x000d;break;case 0x000e:output 0x000e;break;case 0x000f:output 0x000f;break;case 0x0010:output 0x0010;SLAA205B – June 2005 – Revised July 2006Submit Documentation FeedbackMSP430 Competitive Benchmarking23
www.ti.comBenchmarking Application Source Codebreak;} /* end switch*/return (output);}void main(void){volatile UInt16 result;result switch case(0x0010);return;}24MSP430 Competitive BenchmarkingSLAA205B – June 2005 – Revised July 2006Submit Documentation Feedback
www.ti.comBenchmarking Application Source Code32-bit **************************************Name: 32-bit Math*Purpose : Benchmark 32-bit math ****************************************/#include math.h typedef unsigned long UInt32;UInt32 add(UInt32 a, UInt32 b){return (a b);}UInt32 mul(UInt32 a, UInt32 b){return (a * b);}UInt32 div(UInt32 a, UInt32 b){return (a / b);}void main(void){volatile UInt32 lt[3]return; 43125;14567;add(result[0], result[1]);mul(result[0], result[2]);div(result[1], result[2]);}SLAA205B – June 2005 – Revised July 2006Submit Documentation FeedbackMSP430 Competitive Benchmarking25
www.ti.comBenchmarking Application Source CodeFloating-point **************************************Name: Floating-point Math*Purpose : Benchmark floating-point math ****************************************/float add(float a, float b){return (a b);}float mul(float a, float b){return (a * b);}float div(float a, float b){return (a / b);}void main(void){volatile float lt[3]return; 54.567;14346.67;add(result[0], result[1]);mul(result[0], result[2]);div(result[1], result[2]);}26MSP430 Competitive BenchmarkingSLAA205B – June 2005 – Revised July 2006Submit Documentation Feedback
www.ti.comBenchmarking Application Source CodeMatrix me: Matrix Multiplication*Purpose : Benchmark multiplying a 3x4 matrix by a 4x5 matrix.*Matrix contains 16-bit *************************************/typedef unsigned short UInt16;const UInt16 m1[3][4] {{0x01, 0x02, 0x03, 0x04},{0x05, 0x06, 0x07, 0x08},{0x09, 0x0A, 0x0B, 0x0C}};const UInt16 m2[4][5] {{0x01, 0x02, 0x03, 0x04,{0x06, 0x07, 0x08, 0x09,{0x0B, 0x0C, 0x0D, 0x0E,{0x10, 0x11, 0x12, 0x13,};0x05},0x0A},0x0F},0x14}void main(void){int m, n, p;volatile UInt16 m3[3][5];for(m 0; m 3; m ){for(p 0; p 5; p ){m3[m][p] 0;for(n 0; n 4; n ){m3[m][p] m1[m][n] * m2[n][p];}}}return;}SLAA205B – June 2005 – Revised July 2006Submit Documentation FeedbackMSP430 Competitive Benchmarking27
www.ti.comBenchmarking Application Source CodeFIR ****************************************Name: FIR Filter*Purpose : Benchmark an FIR filter. The input values for the filter*is an array of 51 16-bit values. The order of the ****************************************/#ifdef MSP430#include "msp430x14x.h"#endif#include math.h #define FIR LENGTH 17const float COEFF[FIR LENGTH] {-0.000091552734, 0.000305175781, 0.004608154297, 0.003356933594, -0.025939941406,-0.044006347656, 0.063079833984, 0.290313720703, 0.416748046875, 0.290313720703,0.063079833984, -0.044006347656, -0.025939941406, 0.003356933594, 0.004608154297,0.000305175781, -0.000091552734};/* The following array simulates input A/D converted values */const unsigned int INPUT[] {0x0000, 0x0000, 0x0000, 0x0000,0x0000, 0x0000, 0x0000, 0x0000,0x0000, 0x0000, 0x0000, 0x0000,0x0000, 0x0000, 0x0000, 0x0000,0x0400, 0x0800, 0x0C00, 0x1000, 0x1400, 0x1800, 0x1C00, 0x2000,0x2400, 0x2000, 0x1C00, 0x1800, 0x1400, 0x1000, 0x0C00, 0x0800,0x0400, 0x0400, 0x0800, 0x0C00, 0x1000, 0x1400, 0x1800, 0x1C00,0x2000, 0x2400, 0x2000, 0x1C00, 0x1800, 0x1400, 0x1000, 0x0C00,0x0800, 0x0400, 0x0400, 0x0800, 0x0C00, 0x1000, 0x1400, 0x1800,0x1C00, 0x2000, 0x2400, 0x2000, 0x1C00, 0x1800, 0x1400, 0x1000,0x0C00, 0x0800, 0x0400};void main(void){int i, y; /* Loop counters */volatile float OUTPUT[36],sum;#ifdef MSP430WDTCTL WDTPW WDTHOLD; /* Stop watchdog timer */#endiffor(y 0; y 36; y ){sum 0;for(i 0; i FIR LENGTH/2; i ){sum sum COEFF[i] * ( INPUT[y 16 - i] INPUT[y i] );}OUTPUT[y] sum (INPUT[y FIR LENGTH/2] * COEFF[FIR LENGTH/2] );}return;}28MSP430 Competitive BenchmarkingSLAA205B – June 2005 – Revised July 2006Submit Documentation Feedback
www.ti.comBenchmarking Application Source ******************************************Name: Dhrystone*Purpose : Benchmark the Dhrystone code. This benchmark is used to gauge*the performance of the microcontroller in handling pointers,*structures and strings.***********************************
Microcontroller Code size in bytes Unoptimized Optimized Application Report SLAA205B- June 2005- Revised July 2006 . 4 MSP430 Competitive Benchmarking SLAA205B- June 2005- Revised July 2006 Submit Documentation Feedback. www .ti.com 0 200000 400000 600000 800000 1000000 1200000