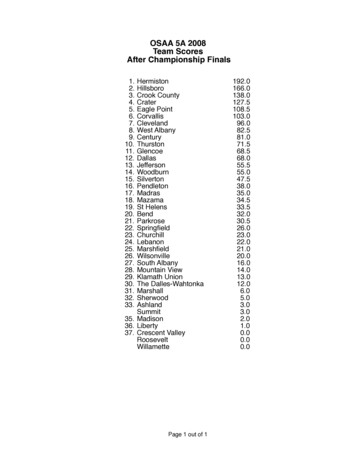
![CS555: Distributed Systems [Fall 2019] Dept. Of Computer Science .](/img/17/cs555-l12-spark-parta.jpg)
Transcription
CS555: Distributed Systems [Fall 2019]Dept. Of Computer Science, Colorado State UniversityFrequently asked questions from the previous classsurveyCS 555: DISTRIBUTED SYSTEMS Custom Partitioners How does Hadoop decide whether or not to call the combiner?[SPARK] How often, example?Shrideep PallickaraComputer ScienceColorado State UniversityOctober 3, 2019CS555: Distributed System s [Fall 2019]L12.1Dept. O f Com puter Science, Colorado State UniversityCS555: Distributed System s [Fall 2019]O ctober 3, 2019Professor: SHRIDEEP PALLICKARAL12.2Dept. O f Com puter Science, Colorado State UniversityTopics covered in this lecture Spark Software stack Interactive shells in SparkCore Spark concepts APACHE SPARKO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distrib uted System s [Fall 2019]L12.3Spark: What is it? Designed to be fast and general purpose Often considered to be a design alternative for Apache MapReduce Extends MapReduce to support more types of computationsn Interactive queries, iterative tasks, and stream processing Why is speed important?Difference between waiting for hours versus exploring data interactivelyO ctober 3, 2019Professor: SHRIDEEP PALLICKARAL12.4Spark has inherited parts of its API, design, and supported formatsfrom other existing computational frameworks Speed CS555: Distributed System s [Fall 2019]Dept. O f Com puter Science, Colorado State UniversitySpark: Influences and InnovationsCluster computing platform October 3, 2019Dept. O f Com puter Science, Colorado State UniversityCS555: Distributed System s [Fall 2019]Dept. O f Com puter Science, Colorado State UniversitySLIDES CREATED BY: SHRIDEEP PALLICKARAL12.5Particularly DryadLINQSpark’s internals, especially how it handles failures, differ from manytraditional systemsSpark’s ability to leverage lazy evaluation within memorycomputations makes it particularly uniqueO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.6Dept. O f Com puter Science, Colorado State UniversityL12.1
CS555: Distributed Systems [Fall 2019]Dept. Of Computer Science, Colorado State UniversityKey enabling idea in SparkWhere does Spark fit in the Analytics Ecosystem? Spark provides methods to process data in parallel that aregeneralizableOn its own, Spark is not a data storage solution Memory-resident data Spark loads data into the memory of worker nodes Performs computations on Spark JVMs that last only for the duration of aSpark applicationProcessing is performed on memory-resident dataSpark is used in tandem with:A distributed storage system (e.g., HDFS, Cassandra, or S3)n To house the data processed with Spark A cluster manager — to orchestrate the distribution of Spark applicationsacross the cluster CS555: Distributed System s [Fall 2019]O ctober 3, 2019Professor: SHRIDEEP PALLICKARAL12.7Dept. O f Com puter Science, Colorado State UniversityA look at the memory hierarchyItemtime0.5 ns (2 GHz)1 secondCache access1 ns (1 GHz)2 secondsMemory access70 ns140 secondsContext switch5,000 ns (5 μs)167 minutesDisk access7,000,000 ns (7 ms)162 daysQuantum100,000,000 ns (100 ms)6.3 yearsCS555: Distributed System s [Fall 2019]L12.8Dept. O f Com puter Science, Colorado State UniversitySpark covers a wide range of workloadsScaled time in human terms(2 billion times slower)Processor cycleO ctober 3, 2019Professor: SHRIDEEP PALLICKARA Batch applicationsIterative algorithms QueriesStream processing This has previously required multiple, independent tools Source: Kay Robbins & Steve Robbins. Unix Systems Programming, 2nd edition, Prentice Hall.O ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distrib uted System s [Fall 2019]L12.9Dept. O f Com puter Science, Colorado State UniversityRunning Spark CS555: Distributed System s [Fall 2019]L12.10Dept. O f Com puter Science, Colorado State UniversitySpark integrates well with other toolsYou can use Spark from Python, Java, Scala, R, or SQLSpark itself is written in Scala, and runs on the Java Virtual Machine(JVM) O ctober 3, 2019Professor: SHRIDEEP PALLICKARA Can run in Hadoop clustersAccess Hadoop data sources, including CassandraYou can Spark either on your laptop or a cluster, all you need is aninstallation of JavaIf you want to use the Python API, you will also need a Pythoninterpreter (version 2.7 or later)If you want to use R, you will need a version of R on your machine.O ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]Dept. O f Com puter Science, Colorado State UniversitySLIDES CREATED BY: SHRIDEEP PALLICKARAL12.11O ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.12Dept. O f Com puter Science, Colorado State UniversityL12.2
CS555: Distributed Systems [Fall 2019]Dept. Of Computer Science, Colorado State UniversityAt its core, Spark is a computational engine Spark is responsible for several aspects of applications that comprise Spark execution Many tasks across many machines (compute clusters)The cluster of machines that Spark will use to execute tasks ismanaged by a cluster manager Responsibilities include:① Scheduling ② DistributionsSpark’s standalone cluster manager, YARN, or MesosWe submit Spark Applications to these cluster managers, which willgrant resources to the application to complete the work③ MonitoringO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.13Dept. O f Com puter Science, Colorado State UniversitySpark applications A driver processn The driver process is absolutely essentialn The heart of a Spark Application and maintains all relevant information during thelifetime of the applicationA set of executor processesO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distrib uted System s [Fall 2019]L12.15Dept. O f Com puter Science, Colorado State UniversityThe executors L12.14Dept. O f Com puter Science, Colorado State UniversityThe DriverSpark Applications consist of CS555: Distributed System s [Fall 2019]O ctober 3, 2019Professor: SHRIDEEP PALLICKARA The driver process runs your main() function, sits on a node in theclusterDriver is responsible for three things: Maintaining information about the Spark Application Responding to a user’s program or input Analyzing, distributing, and scheduling work across the executorsCS555: Distributed System s [Fall 2019]O ctober 3, 2019Professor: SHRIDEEP PALLICKARAL12.16Dept. O f Com puter Science, Colorado State UniversityArchitecture of a Spark ApplicationThe executors are responsible for actually carrying out the work thatthe driver assigns themDriver ProcessSparkSessionEach executor is responsible for only two things: Executing code assigned to it by the driver, and Reporting the state of the computation on that executor back to the drivernodeExecutorsUser CodeCluster ManagerO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]Dept. O f Com puter Science, Colorado State UniversitySLIDES CREATED BY: SHRIDEEP PALLICKARAL12.17O ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.18Dept. O f Com puter Science, Colorado State UniversityL12.3
CS555: Distributed Systems [Fall 2019]Dept. Of Computer Science, Colorado State UniversityHow Spark runs Python or R SparkSessionYou write Python and R code that Spark translates into code that itthen can run on the executor JVMTo executorsJVM We need a way to send user commands and data to a SparkApplication PythonProcess SparkSessionThe SparkSession instance is the way Spark executes user-definedmanipulations across the cluster. There is a one-to-one correspondence between a SparkSession and a SparkApplication In Scala and Python, the variable is available as spark when you start theconsole.R ProcessO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.19Dept. O f Com puter Science, Colorado State UniversityPartitions For e.g., a partition may be a collection of rows that sit on one physicalmachine in your clusterL12.20An important thing to note is that you do not (for the most part)manipulate partitions manually or individually CS555: Distrib uted System s [Fall 2019]L12.21Dept. O f Com puter Science, Colorado State UniversityTransformationsYou simply specify high-level transformations of data in the physicalpartitionsn Spark determines how this work will actually execute on the cluster.O ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.22Dept. O f Com puter Science, Colorado State UniversityMore about transformationsIn Spark, the core data structures are immutable CS555: Distributed System s [Fall 2019]Dept. O f Com puter Science, Colorado State UniversitySpark will still have a parallelism of only one because there is only onecomputation resourceO ctober 3, 2019Professor: SHRIDEEP PALLICKARA If you have one partition, Spark will have a parallelism of only one,even if you have thousands of executorsIf you have many partitions but only one executor? O ctober 3, 2019Professor: SHRIDEEP PALLICKARAManipulation of PartitionsTo allow every executor to perform work in parallel, Spark breaks upthe data into chunks called partitions We do that by first creating a SparkSession They cannot be changed after they’re createdTransformations do not return an output Spark will not act on transformations until we call an actionIf you cannot change it, how are you supposed to use it? You need to instruct Spark how you would like to modify itThese instructions are called transformationsO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]Dept. O f Com puter Science, Colorado State UniversitySLIDES CREATED BY: SHRIDEEP PALLICKARAL12.23O ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.24Dept. O f Com puter Science, Colorado State UniversityL12.4
CS555: Distributed Systems [Fall 2019]Dept. Of Computer Science, Colorado State UniversityLazy evaluation Why lazy evaluation works Spark will wait until the very last moment to execute the graph ofcomputation instructions You do not modify the data immediately Rather, you build up a plan of transformations that you would like to applyto your source data.CS555: Distributed System s [Fall 2019]L12.25Dept. O f Com puter Science, Colorado State University Multiple transformations build up a directed acyclic graph of instructions E.g. predicate pushdownsCS555: Distributed System s [Fall 2019]O ctober 3, 2019Professor: SHRIDEEP PALLICKARAL12.26Dept. O f Com puter Science, Colorado State University Spark has two fundamental sets of APIs: The low-level “unstructured” APIs, and The higher-level structured APIsAs a single jobBy breaking it down into stages and tasks to execute across the clusterO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distrib uted System s [Fall 2019]L12.27Dept. O f Com puter Science, Colorado State UniversityStructured APIsCS555: Distributed System s [Fall 2019]O ctober 3, 2019Professor: SHRIDEEP PALLICKARAL12.28Dept. O f Com puter Science, Colorado State UniversitySpark’s ToolsetStructured APIs are a tool for manipulating all sorts of data StructuredStreamingFrom unstructured log files to semi-structured CSV files and highly structuredParquet filesRefers to three core types of distributed collection APIs: DatasetsDataFrames SQL tables and views This provides immense benefits because Spark can optimize the entiredata flow from end to endAn action begins the process of executing that graph of instructions Spark compiles this plan from your transformations to a streamlined physicalplan that will run as efficiently as possible across the clusterSpark APIsSpark is a distributed programming model in which the user specifiestransformations Spark in a nutshell By waiting until the last minute to execute the codeWhen you express some operation?O ctober 3, 2019Professor: SHRIDEEP PALLICKARA CS555: Distributed System s [Fall 2019]Dept. O f Com puter Science, Colorado State UniversitySLIDES CREATED BY: SHRIDEEP PALLICKARALibraries &EcosystemStructured APIsDatasetsMajority of the Structured APIs apply to both batch and streamingcomputationO ctober 3, 2019Professor: SHRIDEEP PALLICKARAAdvancedAnalyticsDataFramesSQLsLow Level APIsRDDsL12.29O ctober 3, 2019Professor: SHRIDEEP PALLICKARADistributed variablesCS555: Distributed System s [Fall 2019]L12.30Dept. O f Com puter Science, Colorado State UniversityL12.5
CS555: Distributed Systems [Fall 2019]Dept. Of Computer Science, Colorado State UniversitySpark has two notions of structured collections:DataFrames and Datasets DataFrames versus DatasetsDataFrames and Datasets are (distributed) table-like collections withwell-defined rows and columns Must have the same number of rows as all the other columns (although youcan use null to specify the absence of a value) Has type information that must be consistent for every row in the collection.CS555: Distributed System s [Fall 2019]L12.31Dept. O f Com puter Science, Colorado State University DataFrames are considered “untyped”Datasets are considered “typed”O ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.32Dept. O f Com puter Science, Colorado State UniversityThe DataFrame is the most common Structured APIHow does Spark view DataFrames and Datasets? Each column:O ctober 3, 2019Professor: SHRIDEEP PALLICKARA To Spark, DataFrames and Datasets represent immutable, lazilyevaluated plans that specify what operations to apply to dataresiding at a location to generate some output Simply represents a table of data with rows and columnsThe list that defines the columns and the types within those columns iscalled the schemaWhen we perform an action on a DataFrame, we instruct Spark toperform the actual transformations and return the resultThese represent plans of how to manipulate rows and columns tocompute the user’s desired result.O ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distrib uted System s [Fall 2019]L12.33Dept. O f Com puter Science, Colorado State UniversityO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.34Dept. O f Com puter Science, Colorado State UniversityThe DataFrame concept is not unique to Spark R and Python both have similar concepts.However, Python/R DataFrames (with some exceptions) exist on one machinerather than multiple machines This limits what you can do with a given DataFrame to the resources thatexist on that specific machine A Spark DataFrame can span thousands of computers.THE SPARK SOFTWARE STACKO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]Dept. O f Com puter Science, Colorado State UniversitySLIDES CREATED BY: SHRIDEEP PALLICKARAL12.35October 3, 2019CS555: Distributed System s [Fall 2019]L12.36Dept. O f Com puter Science, Colorado State UniversityL12.6
CS555: Distributed Systems [Fall 2019]Dept. Of Computer Science, Colorado State UniversityThe Spark stackSpark SQL(semi-)structureddataSpark CoreSparkStreamingreal-timeMLib & MLmachinelearning GraphXGraphprocessing Spark CoreStandalone SchedulerO ctober 3, 2019Professor: SHRIDEEP PALLICKARAYARNCS555: Distributed System s [Fall 2019]Package for working with structured dataAllows querying data using SQL and HQL (Hive Query Language)L12.37 Represents collection of data items dispersed across many compute nodesAllows intermixing queries with programmatic data manipulationssupport by RDDs Using Scala, Java, and PythonCS555: Distrib uted System s [Fall 2019]L12.39Dept. O f Com puter Science, Colorado State UniversityL12.38And as of Spark 1.6, a semi-structured, typed version of RDDs calledDatasetsMuch of what can be accomplished with Spark Core can be done byleveraging Spark SQL.O ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.40Dept. O f Com puter Science, Colorado State UniversityMLibEnables processing of live streams of data from sources such as: Logfiles generated by production webservers Messages containing web service status updates MLlib is a package of machine learning and statistics algorithmswritten with SparkAlgorithms include: Low-level primitives Alternatives? Uses the scheduling of the Spark Core for streaming analytics onminibatches of dataHas a number of unique considerations, such as the window sizes usedfor batches O ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]Dept. O f Com puter Science, Colorado State UniversitySpark SQL is a very important component for Spark performance Can be manipulated concurrently (parallel)Spark SQL defines an interface for a semi-structured data type,called DataFrames Spark Streaming Spark’s core programming abstraction O ctober 3, 2019Professor: SHRIDEEP PALLICKARAData sources: Hive tables, Parquet, and JSONO ctober 3, 2019Professor: SHRIDEEP PALLICKARA Semi-structured data and Spark SQL Also, the API that defines Resilient Distributed Datasets (RDDs)nDept. O f Com puter Science, Colorado State University Task scheduling, memory management, fault recovery, and interactingwith storage systemsMesosSpark SQL Basic functionality of SparkCS555: Distributed System s [Fall 2019]Dept. O f Com puter Science, Colorado State UniversitySLIDES CREATED BY: SHRIDEEP PALLICKARAL12.41Clustering, classification, regression, clustering, and collaborative filteringGeneric gradient descent optimization algorithmMahout, sci–kit learn, VW, WEKA, and R among othersO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.42Dept. O f Com puter Science, Colorado State UniversityL12.7
CS555: Distributed Systems [Fall 2019]Dept. Of Computer Science, Colorado State UniversityWhat about Spark ML?Graph X Still in the early stages, and has only existed since Spark 1.2 Library for manipulating graphs Spark ML provides a higher-level API than MLlib Graph-parallel computations Extends Spark RDD APIGoal is to allow users to more easily create practical machine learningpipelines Spark MLlib is primarily built on top of RDDs and uses functions from SparkCore, while ML is built on top of Spark SQL DataFrames Create a directed graph, with arbitrary properties attached to each vertexand edgeEventually the Spark community plans to move over to ML anddeprecate MLlibCS555: Distributed System s [Fall 2019]O ctober 3, 2019Professor: SHRIDEEP PALLICKARAL12.43Dept. O f Com puter Science, Colorado State UniversityCluster ManagersO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.44Dept. O f Com puter Science, Colorado State UniversityStorage Layers for Spark Spark runs over a variety of cluster managers Spark can create distributed datasets from any file stored in HDFS These include: Plus, other storage systems supported by the Hadoop API Hadoop YARN Amazon S3, Cassandra, Hive, HBase, etc.Apache Mesos Standalone Schedulern Included within Spark O ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distrib uted System s [Fall 2019]L12.45Dept. O f Com puter Science, Colorado State UniversityO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.46Dept. O f Com puter Science, Colorado State UniversitySpark Shells Interactive [Python and Scala] Ad hoc data analysis INTERACTIVE SHELLS IN SPARKOctober 3, 2019CS555: Distributed System s [Fall 2019]Dept. O f Com puter Science, Colorado State UniversitySLIDES CREATED BY: SHRIDEEP PALLICKARAL12.47Similar to shells like Bash or Windows command promptTraditional shells manipulate data using disk and memory on a singlemachine Spark shells allow interaction with data that is distributed across manymachines Spark manages complexity of distributing processingO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.48Dept. O f Com puter Science, Colorado State UniversityL12.8
CS555: Distributed Systems [Fall 2019]Dept. Of Computer Science, Colorado State UniversitySeveral software were designed to run on the JavaVirtual Machine Languages that compile to run on the JVM and can interact with Javasoftware packages but are not actually Java There are a number of non-Java JVM languages The two most popular ones used in real-time application development: Scalaand ClojureO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.49Dept. O f Com puter Science, Colorado State UniversityWhat is functional programming? Scala Still largely developed at universities Has a rich standard library that has made it appealing to developers ofhigh-performance server applicationsLike Java, Scala is a strongly typed object-oriented language Includes many features from functional programming languages that are notin standard Java Interestingly, Java 8 incorporate several of the more useful features ofScala and other functional languages.O ctober 3, 2019Professor: SHRIDEEP PALLICKARAThen largely disappears from the Java environmentExcept when it is called by other methods Based on Lisp Javascript? n CS555: Distributed System s [Fall 2019]L12.50Dept. O f Com puter Science, Colorado State UniversityWhat about Clojure?When a method is compiled by Java, it is converted to instructionscalled byte code and Has spent most of its life as an academic languageName was a marketing gimmickCloser to Clojure and Scala than it is to JavaIn a functional language, functions are treated the same way as data Can be stored in objects similar to integers or strings, returned fromfunctions, and passed to other functionsO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distrib uted System s [Fall 2019]L12.51Dept. O f Com puter Science, Colorado State UniversityO ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.52Dept. O f Com puter Science, Colorado State UniversityThe contents of this slide-set are based on thefollowing references Learning Spark: Lightning-Fast Big Data Analysis. 1st Edition. Holden Karau, AndyKonwinski, Patrick Wendell, and Matei Zaharia. O'Reilly. 2015. ISBN-13: 9781449358624. [Chapters 1-4] Karau, Holden; Warren, Rachel. High Performance Spark: Best Practices for Scalingand Optimizing Apache Spark. O'Reilly Media. 2017. ISBN-13: 978-1491943205.[Chapter 2]Chambers, Bill,Zaharia, Matei. Spark: The Definitive Guide: Big Data ProcessingMade Simple. O'Reilly Media. ISBN-13: 978-1491912218. 2018. [Chapters 1, 2,and 3]. Real-Time Analytics: Techniques to Analyze and Visualize Streaming Data. Byron Ellis.Wiley. [Chapter 2]O ctober 3, 2019Professor: SHRIDEEP PALLICKARACS555: Distributed System s [Fall 2019]L12.53Dept. O f Com puter Science, Colorado State UniversitySLIDES CREATED BY: SHRIDEEP PALLICKARAL12.9
SLIDESCREATEDBY: SHRIDEEPPALLICKARA L12.3 CS555: Distributed Systems[Fall 2019] Dept. Of Computer Science, Colorado State University CS555: Distributed Systems[Fall 2019] Dept. Of Computer Science, Colorado State University L12.13 Professor: SHRIDEEPPALLICKARA At its core, Spark is a computational engine Spark is responsible for several aspects of applications that comprise