Transcription
Advances in Engineering Research, volume 1273rd International Conference on Electrical, Automation and Mechanical Engineering (EAME 2018)A Fast Quality Scalable Video Coding Method Basedon Compressed SensingMin Sun1, Dong Hu2,* and Jianyu Ding31Education Ministry’s Key Lab of Broadband Wireless Communication and Sensor Network Technology2Education Ministry’s Engineering Research Center of Ubiquitous Network and Heath Service3Jiangsu Province’s Key Lab of Image Procession and Image Communications, Nanjing University of Posts andTelecommunications, Nanjing, 210003, China*Corresponding authorAbstract—This paper presents a fast quality scalable videocoding method based on compressed sensing(CS). The proposedmethod obtained the coding scheme of the enhancement MJU byusing the interlayer and spatial correlation and kept the baselayer’s coding scheme unchanged. And the part in theenhancement layer which needed to be fine quantified wascombined with the compressed sensing theory selectively whichbased on the sparsity of the signal and the complexity of thereconstruction. In order to satisfy the coding syntax structure ofthe reference software, the measurement value got by compressedsensing was complemented by 0s and the flag bit was set todistinguish the special sub-blocks coded by CS. Experimentalresults show that the proposed algorithm can effectively improvethe efficiency of scalable video coding and reduce thecomputational complexity.Keywords—video coding; compressed sensing; quality scalablevideo codingI.INTRODUCTIONDifferent from the traditional video coding methods,scalable video coding can not only provide video services todifferent end users, but also can automatically choose differentcoding methods according to different terminal scenarios andrequirements. In the earlier studies, researchers focused onscalable video coding fast algorithms that aimed to reduced itscoding complexity. Seon-Tae Kim [1] et al. obtained aweighted model and proposed a fast mode decision algorithmfor coarse-grained quality scalability based on correlationbetween layers. Yu Che [2] et al. proposed a probabilisticmodel predicting the probability of motion vectors and nonzero coefficients for all scalable video coding. Althoughresearchers have reduced the computational complexity ofscalable video coding to a certain extent, they have not reallysolved the problem of huge resource consumption caused byenhancement layer of scalable video coding.In recent years, the CS has been a natural tool to reduce thenumber of samples, then more and more researchers began totake the advantages of CS to solve the problems in scalablevideo coding. For example, in [3] the authors proposed ascheme for compressed sampling that exploits local sparsitywithin a frame applied to wireless network environments. Thecoding framework improves the coding efficiency byabandoning motion estimation and motion compensation, andonly read key frames for reference to reduce the complexity.In [4] Vladimir Stankovic and others proposed a scalablecoding framework that improved the base layer coding qualityby changing the measurement matrix in compressed sensing,improving the quality of the base layer video image.Compared with previous fast algorithms which decide thecoding scheme depending on statistical information, qualityscalable video coding based on compressed sensing canimprove the performance of scalable video coding moremeticulously and effectively. The focus of this paper is toapply sparsity theory to quality scalable video coding andcombine compressed sensing with a fast quality scalablecoding framework.The rest of the paper is organized as follows. Section IIgives a brief introduction of compressed sensing. Section IIIdescribes the architecture of fast quality scalable video codingbased on CS. The performance of fast quality scalable videocoding based on CS is studied in section IV, followed byconcluding remarks in section V.II.BACKGROUNDCompressed sensing or sampling [5][6] was proposed as anew acquisition framework which can sample and compresssparsity or compressible signals in a single operation. Supposethat a signal x R n can be transformed to a coefficient vectorθ with some basis , x . can be any representingbasis such as DCT or wavelet [7]. The measurements ofcompressed sensing, y R m , are obtained by multiplyingsignal x with a measurement matrix R m n , i.e., y x .Since m n, (1) is an underdetermined system with infinitesolutions. Using the reverse operation in (1) to recover x isinfeasible. Finally, complete content and organizationalediting before formatting [8]. Please take note of the followingitems when proofreading spelling and grammar:y x(1)To make recovery stable and accurate, sensing matrix Φmust satisfy the restricted isometry property (RIP). Reference[6] showed the methods of generating sensing matrix holdingCopyright 2018, the Authors. Published by Atlantis Press.This is an open access article under the CC BY-NC license 6
Advances in Engineering Research, volume 127RIP. One of them is to randomly select m rows from theFourier matrix or Gaussian random matrix.When the original signal x is measured to form themeasurement value y, it is necessary to reconstruct originalsignal in the decode side. OMP reconstruction algorithm isadopted in this paper [9]. The algorithm first performsSchmidt orthogonalization for selected atoms, and then thesignal is projected on the space of the atoms that are processedby orthogonalization, and finally the projection components ofthe signal in the selected atomic space are calculated. Theadvantage of this method is that it can guarantee that theresiduals used in each iteration after schmidt'sorthogonalization process are orthogonal to the selected atoms,so it can effectively speed up the convergence speed of thealgorithm and improve the efficiency of the algorithm [10].parameters are configured as follows: the quantizationparameters of the base layer and the enhancement layer are 24and 32 respectively; the GOP size is 4, the video sequencessize are 1280 720, the experiment results are shown in theTable I.Table I shows results of the Inter-layer correlation betweenbase layer and enhancement layer in 1280x720 video sequence.We can see that the best coding mode of enhancement layerhas a certain correlation with the base layer coding mode.TABLE I. CORRELATION BETWEEN BASE LAYER ANDENHANCEMENT LAYER IN 1280 720 VIDEO SEQUENCE (%)VideoSequenceELBLIII.PROPOSED VIDEO CODING ALGORITHMIn this section, we describe the proposed fast qualityscalable video coding scheme based on the compressedsensing. Our work is divided into two parts. The first is toanalyze the correlation between the base layer and theenhancement layer, then use the sub-blocks that have beencoded in the base layer to obtain sub-blocks of theenhancement layer quickly. The second part combines subblocks with compressed sensing theory to achieve the effect ofreducing the coding rate of the encoder.A. Correlation Analysis1) Spatial correlation analysis:Spatial correlation means that neighboring macroblockshave a high degree of similarity in their motion characteristicsand structural characteristics, which leads to a very highcorrelation between their coding modes. When the spatialcorrelation is used for prediction, the correlation degreebetween the current macroblock and adjacent macroblocks,that is probabilistic meaning between them, must be obtainedprimarily. The spatial correlation of the enhancement layer canthen be used to judge the spatial correlation of theenhancement layer. When the correlation between theneighboring blocks of the base layer is greater, the probabilitythat the neighboring blocks of the enhancement layer at thesame position use the same pattern is greater. Thesecorrelations are not only manifested in the type ofmacroblocks, but also in the spatial position of macroblocks.Spatial correlation can provide an effective basis for the nextfast mode decision.2) Inter-layer correlation:In quality scalable video coding, the base layer and theenhancement layer have the same resolution and frame rate,only the quantization steps are different, so the base layer andenhancement layer are similar in coded macroblocks, namelyinter-layer correlation. To illustrate the correlation between thebase layer and the enhancement layer clearly, the experimentcode different sizes test sequences and calculate the degree ofcorrelation between the base layer and enhancement layer incase of 16 16, 16 8, 8 16, 8 8, and the SKIP moderespectively. This experiment is performed in the H.264[11]standard code reference software JSVM 9.18. The relevantSKIPPartySceneParkRunterParkJoyConditional Probability DistributionSKIP16 1616 88 168 80.7010.1240.0330.0420.08916 160.2620.5760.0450.0510.05616 80.1020.1930.3880.0380.2798 160.1200.2060.0750.3100.2888 0.02316 160.2710.5120.0690.0630.05416 80.1210.1350.3770.1130.2548 160.1480.1780.0620.3520.2608 0.10716 160.2590.5610.0640.0570.05916 80.1420.1580.3630.0600.2878 160.1140.1940.1000.3460.2768 80.1510.1770.1670.1520.358B. Fast Mode Selection ModelTo accelerate the selection of enhancement layer codingmodes and reduce coding complexity effectively, we proposedearly termination conditions for spatial and inter-layercorrelation. Since the macroblocks content are approximatelysimilar in the same position of base layer and enhancementlayer, it also means that the different of quantization steps doesnot play an important role in the mode selection. Therefore,the early termination condition between layers can beestimated by:ze zb k1(2) where ze and zb are the quantization coefficients of the baselayer and the enhancement layer, respectively, and k1 isthreshold from experiment. Formula (2) can be written as:67
Advances in Engineering Research, volume 127re Qe rb / Qb k1Qe(3)where Qb , Qe are the quantization steps of base layer andenhancement layer respectively, rb and re are DCTcoefficients of base layer and enhancement layer respectively.Since the DCT coefficients calculation can be described as:3r 3 diu xuv d jvu 0 v 0(4)where diu is the value of (i, u ) in the integer DCT transform,xuv is the residual signal value, since d jv is less than32, so532r xuv5 u 0 v 0 (5)combine (2) and (5), that can be describe as:33 3exuv Qestepu 0 v 03 xbuvu 0 v 0/Qbstep 5k1Qestep2(6)C. Fast Quality Scalable Coding Algorithm Based on CSWhen we combined inter-frame coding with CS, the signalmeets the sparsity requirements so we can compress the signalin a high rate. In scalable video coding, signal of theenhancement layer, especially the enhancement layer of theinter-frame coding, is a residual signal with a high degree ofsparsity, so it naturally meets the sparsity demand. Therefore,the sub-block selected by the quick mode combined with CScan improve the efficiency of the encoding.When compressed sensing is combined with inter-framecoding, it has a high compression rate because it can achievethe sparsity requirement of the signal. In scalable video coding,the enhancement layer especially enhancement inter-framecoding layer, the residual signals of the signal can satisfy therequirement of the signal sparsity. Therefore, it can reduce theefficiency of coding by combining the compressed sensingwith the sub-block selected by fast mode. When theenhancement layer is sparse, it does bring down the reductionof the coding end code of the scalable video encoding, whichimproves the coding efficiency greatly.However, due to the sparsity representation of allenhancement layer sub-block modes, the computationalcomplexity of the reconstruction algorithm will be very high.The next step is to do a detailed analysis of computationalcomplexity for the different macroblocks with sparsityrepresentation. Since the 4 4 block have not met therequirements of sparsity, there is no prerequisite for measuringthe sparsity. Therefore, only 8 8 blocks and 16 16 blocks areused for reference comparison. The experimental performancereference indexes are Bitrate , PSNR , Time , thecalculation formula is:Bitrate8 Bitrate16 100%Bitrate8(9) PSNR PSNR8 PSNR16(10)Time8 Time16 100%Time8(11) Bitrate When conditionRDe Qe RDb / Qb 40k1Qe(7)is satisfied, the selection of the inter-layer decision mode ends,where RD is the rate-distortion cost, which is the constantobtained from experiments, and the best is 2.43. According tothe spatial correlation of DCT quantized coefficients, similarcondition of early termination of spatial correlation isproposed as:RD1 RD2 Qestep ( RD3 RD4 ) / Qbstep 5k2 Qestep2(8) Time The experimental comparison results are shown in theTable II.When spatial correlation meets formula (8), mode selectionends.68
Advances in Engineering Research, volume 127TABLE II. PERFORMANCE COMPARISON OF 8 8 MACROBLOCKAND 16 16 StockholmterIntotreeQP(BL,EL)(30,22) Bitrate(%) PSNR(dB) From the Table II we can see that when 16 16macroblocks are combined with compressed sensing, thecomplexity of its reconstruction algorithm is about 3 times of8 8 blocks, and its code rate is not significantly improved.Therefore, in this paper, only 8 8 blocks are sparselyrepresented in the quality scalable fast coding method, it cannot only provide reliable guarantee for the accuracy ofencoding, but also alleviate the sharp increase of codingalgorithm complexity.Since the sparsity and measurement matrices used in thecompressed sensing process need to satisfy the principle ofRIP, DCT or DWT is often used as a sparse matrix andGaussian random matrices or Bernoulli matrices are used asmeasurement matrices in actual experiments. Integer DCTtransform has been used in the reference software JSVM of theH.264 standard video coding. Therefore, this algorithmchooses integer DCT as the sparse matrix and uses Gaussianrandom matrix as the measurement matrix. The specific stepsof the algorithm are as follows:Step 1: Initialize the parameters: (1) Generate a 64 64Gaussian random matrix using Gaussian random function. (2)Set the scalable video coding layer to 2, one is base layer andthe other is enhancement layer.Step 2: Judge whether the current frame code is base layercode, and if so, keep the original code mode; if not, obtain theblock mode of the enhancement layer by the fast modeselecting condition.Step 3: Judge whether the current enhancement layer subblock contains the flag transform size 8 8 flag. If not,perform fine-quantization coding according to the originalmode.(1) Sparse the 8 8 sub-blocks using an integer DCT, thentransform the 8 8 sparse block to a 64 1 sparse vector N .(2) Select a Gaussian random matrix of size m N as themeasurement matrix for the CS according to the sparsity k ofthe vector N . Multiply the sparse vector N with a Gaussianrandom matrix to obtain a measurement M of size m*1.(3) In order to satisfy the coding syntax structure of thereference software, the measurement value M iscomplemented by 0s and the flag bit Fm is set, and thenentropy coding is performed.Step 5: Judge whether the block to be decoded has a flagbit at the decoder side. If not, perform the normal decodingstep; otherwise, use the and m to calculate M and ,then reconstruct the original signal using the OrthogonalMatching Pursuit (OMP) algorithm.IV.EXPERIMENTIn this section, we carry out experiments on fast qualityscalable fast coding architecture based on CS follow the abovesteps in section III. The test sequences are ParkScene,ParkRunter, ParkJoy, Stockholmter and Intotree. Theexperiments are performed on the standard reference softwareJSVM9.18 of H.264. The relevant configuration is as follows:1) Number of coded frames: 200;2) GOP size: 4;3) Video resolution: base layer: 1280 720, enhancementlayer: 1280 720;4) Quantization step: (30, 22) (30, 24) (30, 26) (30, 28) and(38, 30) (38, 32) (38, 34) (38, 36).The Quantization Parameter(QP) of the first set ofexperiments are (30,22) (30,24) (30,26) (30,28). Table IIIshows the results of the first set of experiments. The QP of thesecond set of experiments are (38,30) (38,32) (38,34) (38,36).Table IV shows the results of the second set of experiments. Inaddition, Figure I shows the comparison between coding anddecoding image of the video sequences PartyScene andParkRunter.The following indexes are used to evaluate the algorithmexperiments results presented in this paper: PSNR indicates the increase in Peak Signal to NoiseRatio(PSNR). The formula is as follows: PSNR PSNRJSVM PSNR proposed(12)where in, the PSNRJSVM obtained from the standard referencesoftware JSVM9.18 of H.264, PSNR proposedStep 4: After the 8 8 sub-blocks are quantized and thensparsely coded as follows:69
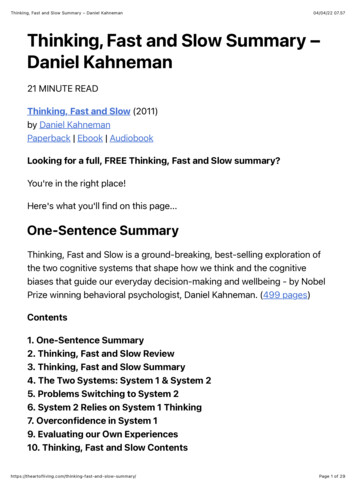
Advances in Engineering Research, volume 127TABLE III. EXPERIMENTAL RESULTS OF FAST QUALITY SCALABLEALGORITHM BASED ON CS (GROUP mterIntotree PSNR /dQP(BL,EL) Bitrate 7.570.073(30,26)28.880.057(30,28)34.640.063TABLE IV. EXPERIMENTAL RESULTS OF FAST QUALITYSCALABLE ALGORITHM BASED ON CS (GROUP mterIntotreeQP(BL,EL) Bitrate /% PSNR nts the PSNR obtained by this algorithm. Bitrate indicates the reduction of the enhancement layerbitrate. The formula is as follows: Bitrate BitrateJSVM Bitrate proposedBitrateJSVM 100%(13)where BitrateJSVM represents the encoding bit rate of thestandard reference software JSVM9.18 of H.264, andBitrateproposed represents the encoded bit rate of the proposedalgorithm. Our presented results reduce the rate bit thanreference JSVM9.18.The effects on PSNR and bit rate are given in Table III andTable IV, which show the increasement of PSNR andreduction of Bitrate. And our algorithm can keep the reductionof PSNR in an acceptable range and improve the bit rateobviously. Figure I is the coding images and decoding imagesof two video sequences, we can see that our algorithm keepsthe image quality unchanged.(A) PARTYSCENE CODING IMAGE(B) PARTYSCENE DECODING IMAGE(C) PARKRUNTER CODING IMAGE(D) PARKRUNTER DECODING IMAGEFIGURE I. FAST QUALITY SCALABLE VIDEO CODING BASED ON CSCODING AND DECODING IMAGE COMPARISONV.CONCLUSIONIn this paper, we proposed a low-complexity, fast qualityscalable video coding architecture based on compressed70
Advances in Engineering Research, volume 127sensing. As the proposed algorithm significantly achievesgood scalability and reduces the coding rate of enhancementlayer, it is more effective and efficient than the traditionalsolution of video coding. While fully exploiting the inter-layerand spatial correlation and residual sparsity, it also guaranteesthe quality of video coding. At the same time, the operation ofzero-filling for measured value also makes the method satisfythe standard coding syntax so it is practical in current videocoding standard reference software.REFERENCES[1]Seon-Tae Kim, Krishna Reddy Konda, ChunSu Park, ChangSik Cho,SungJea Ko, Fast Mode Decision Algorithm for Inter-Layer CodinginScalable Video Coding, IEEE Transactions on Consumer Electronics,vol. 55, no. 3, 1572-1580, 2009.[2] Yu Che Wey, MeiJuan Chen, ChiaHung Yen, ChiaYen Chen, Fast ModeDecision Algorithm for Scalable Video Coding Based on ProbabilisticModels[J], Information and Engineering, vol. 32, no. 5, 931-945, 2016[3] Siyuan Xiang, Lin Cai, Scalable Video Coding with CompressiveSensing for Wireless Videocast, International Conference onCommunication(ICC), IEEE, 1-5, 2011[4] Vladimir Stankovic, Lina Stankovic, Scalable compressive video, InImage Processing(ICIP), IEEE, 921-924, 2011[5] Donoho D L. Compressed sensing[J]. IEEE Transactions on InformationTheory, 2006, 52(4):1289-1306.[6] Candès E J. Compressive Sampling[J]. Marta Sanz Solé, 2006, 17(2):.1433-1452.[7] J. Chen, J. Boyce, Y. Yan and M. M. Hannuksela, G. J. Sullivan, Y-K.Wang. Scalable High Efficiency Video Coding Draft 7, JCTVC-R1008,18th JCTVC Meeting, Sapporo, JP, 2014.[8] S. N. Karishma, B. K. N. Srinivasarao, Indrajit Chakrabarti,Compressive Sensing based Scalable Video Coding for SpaceApplications, In National Conference on Communication(NCC), IEEE,1-6, 2016.[9] Hong Jiang, Chengbo Li, Raziel Haimei-Cohen, Paul A. Wilford, YinZhang, Scalable Video Coding Using Compressive Sensing[J], Bell LabsTechnical Journal, vol.16, no. 4, 149-170, 2012.[10] Zhang Y, Mei S, Chen Q, et al. A novel image/video coding methodbased on Compressed Sensing theory[C]. IEEE International Conferenceon Acoustics, Speech and Signal Processing. IEEE, 2008:1361-1364.[11] T. Wiegand, G. J. Sullivan, G. Bjøntegaard, and A. Luthra. Overview ofthe H.264/AVC video coding standard, IEEE Trans. Circuits Syst.VideoTechnol, 2003, 13(7): 560-576.71
coding complexity. Seon-Tae Kim [1] et al. obtained a weighted model and proposed a fast mode decision algorithm for coarse-grained quality scalability based on correlation between layers. Yu Che [2] et al. proposed a probabilistic model predicting the probability of motion vectors and non-zero coefficients for all scalable video coding. Although