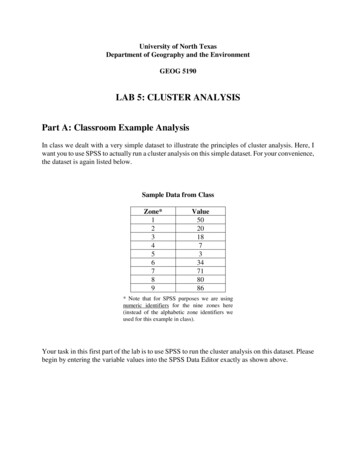
Transcription
Data MiningCluster Analysis: Basic Conceptsand AlgorithmsLecture Notes for Chapter 7Introduction to Data Mining, 2nd EditionbyTan, Steinbach, Karpatne, Kumar with some additions by your instructor
PreliminariesClassification and Clustering
Classification problem A set of objects, each of themdescribed by some features people described by age, gender,height, etc. bank transactions described by type,amount, time, etc.Feature 2(e.g. Income) What we have “good customer” vs. “churner” “normal transaction” vs. “fraudulent” “low risk patient” vs. “risky”?15k ?35k What we want to do Associate the objects of a set to aclass, taken from a predefined list?50y 60yFeature 1(e.g. Age)
Classification problem What we know No domain knowledge or theory Only examples: Training Set Subset of labelled objects What we can do Learn from examples Make inferences about the otherobjects
Classify by similarity K-Nearest Neighbors Decide label based on K most similar examplesK 3
Build a model Example 1: linear separation line
Build a model Example 2: Support Vector Machine (linear)
Build a model Example 3: Non-linear separation line
Build a modelIncome 15k ?yesnoIncome Decision TreesAge 50y ?yesnoAge
Clustering Classification starts from predefined labels andsome examples to learn
Clustering What if no labels are known? We might lack examples Labels might actually not exist at all
Clustering Objective: find structure in the data Group objects into clusters of similar entities
Clustering: K-means (family) Find k subgroups that form compact and wellseparated clustersCluster compactnessK 3Cluster separation
Clustering: K-means (family) Output 1: a partitioning of the initial set of objectsK 3
Clustering: K-means (family) Output 2: K representative objects (centroids) Centroid average profile of the objects in the clusterK 3 Avg. ageAvg. weightAvg. incomeAvg. .n children
Clustering: hierarchical approaches Sometimes we can have (or desire) multiple levelsof aggregation
Clustering: hierarchical approachesDendogram Sometimes we can have (or desire) multiple levelsof aggregation
BasicsThe many notions of «cluster»
What is Cluster Analysis? Finding groups of objects such that the objects in a groupwill be similar (or related) to one another and differentfrom (or unrelated to) the objects in other groupsIntra-clusterdistances areminimized02/14/2018Introduction to Data Mining, 2nd EditionInter-clusterdistances aremaximized19
Applications of Cluster Analysis Understanding– Group related documentsfor browsing, group genesand proteins that havesimilar functionality, orgroup stocks with similarprice fluctuations Discovered N,Compaq-DOWN, EMC-Corp-DOWN, y NOil-UPSummarization– Reduce the size of largedata setsClustering precipitationin Australia02/14/2018Introduction to Data Mining, 2nd Edition20
What is not Cluster Analysis? Simple segmentation– Dividing students into different registration groupsalphabetically, by last name Results of a query– Groupings are a result of an external specification– Clustering is a grouping of objects based on the data Supervised classification– Have class label information Association Analysis– Local vs. global connections02/14/2018Introduction to Data Mining, 2nd Edition21
Notion of a Cluster can be AmbiguousHow many clusters?Six ClustersTwo ClustersFour Clusters02/14/2018Introduction to Data Mining, 2nd Edition22
Types of Clusterings A clustering is a set of clusters Important distinction between hierarchical andpartitional sets of clusters Partitional Clustering– A division of data objects into non-overlapping subsets(clusters) such that each data object is in exactly one subset Hierarchical clustering– A set of nested clusters organized as a hierarchical tree02/14/2018Introduction to Data Mining, 2nd Edition23
Partitional ClusteringOriginal Points02/14/2018A Partitional ClusteringIntroduction to Data Mining, 2nd Edition24
Hierarchical Clusteringp1p3p4p2p1 p2Traditional Hierarchical Clustering02/14/2018p3 p4Traditional DendrogramIntroduction to Data Mining, 2nd Edition25
Other Distinctions Between Sets of Clusters Exclusive versus non-exclusive– In non-exclusive clusterings, points may belong to multipleclusters.– Can represent multiple classes or ‘border’ points Fuzzy versus non-fuzzy– In fuzzy clustering, a point belongs to every cluster with someweight between 0 and 1– Weights must sum to 1– Probabilistic clustering has similar characteristics Partial versus complete– In some cases, we only want to cluster some of the data Heterogeneous versus homogeneous– Clusters of widely different sizes, shapes, and densities02/14/2018Introduction to Data Mining, 2nd Edition26
Types of Clusters Well-separated clusters Center-based clusters Contiguous clusters Density-based clusters Property or Conceptual Described by an Objective Function02/14/2018Introduction to Data Mining, 2nd Edition27
Types of Clusters: Well-Separated Well-Separated Clusters:– A cluster is a set of points such that any point in a cluster iscloser (or more similar) to every other point in the cluster thanto any point not in the cluster.3 well-separated clusters02/14/2018Introduction to Data Mining, 2nd Edition28
Types of Clusters: Center-Based Center-based– A cluster is a set of objects such that an object in a cluster iscloser (more similar) to the “center” of a cluster, than to thecenter of any other cluster– The center of a cluster is often a centroid, the average of allthe points in the cluster, or a medoid, the most “representative”point of a cluster4 center-based clusters02/14/2018Introduction to Data Mining, 2nd Edition29
Types of Clusters: Contiguity-Based Contiguous Cluster (Nearest neighbor orTransitive)– Each point is closer to at least one point in its cluster than toany point in another cluster.– Graph based clustering This approach can have trouble when noise is present since asmall bridge of points can merge two distinct clusters8 contiguous clusters02/14/2018Introduction to Data Mining, 2nd Edition30
Types of Clusters: Density-Based Density-based– A cluster is a dense region of points, which is separated bylow-density regions, from other regions of high density.– Used when the clusters are irregular or intertwined, and whennoise and outliers are present.6 density-based clusters02/14/2018Introduction to Data Mining, 2nd Edition31
Types of Clusters: Objective Function Clusters Defined by an Objective Function– Finds clusters that minimize or maximize an objectivefunction.– Enumerate all possible ways of dividing the points intoclusters and evaluate the goodness' of each potentialset of clusters by using the given objective function.(NP Hard)– Can have global or local objectives.02/14/2018 Hierarchical clustering algorithms typically have local objectives Partitional algorithms typically have global objectivesIntroduction to Data Mining, 2nd Edition32
Characteristics of the Input Data Are Important Type of proximity or density measure– Central to clustering– Depends on data and application Data characteristics that affect proximity and/or density are– Dimensionality Sparseness– Attribute type– Special relationships in the data For example, autocorrelation– Distribution of the data Noise and Outliers– Often interfere with the operation of the clustering algorithm02/14/2018Introduction to Data Mining, 2nd Edition33
MethodsThree fundamental clustering algorithms
Clustering Algorithms K-means and its variants Hierarchical clustering Density-based clustering02/14/2018Introduction to Data Mining, 2nd Edition35
K-means Clustering Partitional clustering approach Number of clusters, K, must be specified Each cluster is associated with a centroid (center point) Each point is assigned to the cluster with the closestcentroid The basic algorithm is very simple02/14/2018Introduction to Data Mining, 2nd Edition36
Example of K-means Clustering
Example of K-means ClusteringIteration 61234532.52y1.510.50-2-1.5-1-0.50x0.511.52
Example of K-means ClusteringIteration 1Iteration 2Iteration 1-0.500.511.52-2-1.5-1-0.5x00.511.52-2Iteration 4Iteration 11.5200.511.5211.52y2.5y2.5y3-1-0.5Iteration n to Data Mining, 2nd Edition-2-1.5-1-0.500.5x39
K-means Clustering – Details Initial centroids are often chosen randomly.–Clusters produced vary from one run to another. The centroid is (typically) the mean of the points in thecluster. ‘Closeness’ is measured by Euclidean distance, cosinesimilarity, correlation, etc. K-means will converge for common similarity measuresmentioned above. Most of the convergence happens in the first fewiterations.– Often the stopping condition is changed to ‘Until relatively fewpoints change clusters’Complexity is O( n * K * I * d )–02/14/2018n number of points, K number of clusters,I number of iterations, d number of attributesIntroduction to Data Mining, 2nd Edition40
Evaluating K-means Clusters Most common measure is Sum of Squared Error (SSE)– For each point, the error is the distance to the nearest cluster– To get SSE, we square these errors and sum them.KSSE dist2(m i, x )i 1 x C i x is a data point in cluster Ci and mi is the representativepoint for cluster Ci can show that mi corresponds to the center (mean) ofthe clusterGiven two sets of clusters, we prefer the one with thesmallest errorOne easy way to reduce SSE is to increase K, the number ofclustersA good clustering with smaller K can have a lower SSE thana poor clustering with higher K02/14/2018Introduction to Data Mining, 2nd Edition41
Two different K-means Clusterings32.5Original .511.52xOptimal Clustering02/14/2018-1Sub-optimal ClusteringIntroduction to Data Mining, 2nd Edition42
Limitations of K-means K-means has problems when clusters are ofdiffering– Sizes– Densities– Non-globular shapes K-means has problems when the data containsoutliers.02/14/2018Introduction to Data Mining, 2nd Edition43
Limitations of K-means: Differing SizesOriginal Points02/14/2018K-means (3 Clusters)Introduction to Data Mining, 2nd Edition44
Overcoming K-means LimitationsOriginal PointsK-means ClustersOne solution is to use many clusters.Find parts of clusters, but need to put together.02/14/2018Introduction to Data Mining, 2nd Edition45
Limitations of K-means: Differing DensityOriginal Points02/14/2018K-means (3 Clusters)Introduction to Data Mining, 2nd Edition46
Overcoming K-means LimitationsOriginal Points02/14/2018K-means ClustersIntroduction to Data Mining, 2nd Edition47
Limitations of K-means: Non-globular ShapesOriginal Points02/14/2018K-means (2 Clusters)Introduction to Data Mining, 2nd Edition48
Overcoming K-means LimitationsOriginal Points02/14/2018K-means ClustersIntroduction to Data Mining, 2nd Edition49
Empty Clusters K-means can yield empty clusters6.56.56.81318XXX91015 1618.57.7512.517.25XXX91015 1618.5EmptyCluster02/14/2018Introduction to Data Mining, 2nd Edition50
Handling Empty Clusters Basic K-means algorithm can yield emptyclusters Several strategies Choose a point and assign it to the cluster Choosethe point that contributes most to SSE Choosea point from the cluster with the highest SSEIf there are several empty clusters, the above canbe repeated several times.02/14/2018Introduction to Data Mining, 2nd Edition51
Pre-processing and Post-processing Pre-processing– Normalize the data– Eliminate outliers Post-processing– Eliminate small clusters that may represent outliers– Split ‘loose’ clusters, i.e., clusters with relatively highSSE– Merge clusters that are ‘close’ and that have relativelylow SSE– Can use these steps during the clustering process 02/14/2018ISODATAIntroduction to Data Mining, 2nd Edition52
Importance of Choosing Initial CentroidsIteration 61234532.52y1.510.50-2-1.5-1-0.50x0.511.52
Importance of Choosing Initial CentroidsIteration 1Iteration 2Iteration 1-0.500.511.52-2-1.5-1-0.5x00.511.52-2Iteration 4Iteration 11.5200.511.5211.52y2.5y2.5y3-1-0.5Iteration n to Data Mining, 2nd Edition-2-1.5-1-0.500.5x54
Importance of Choosing Initial Centroids Iteration 5123432.52y1.510.50-2-1.5-1-0.50x0.511.52
Importance of Choosing Initial Centroids Iteration 1Iteration -2-1.5-1-0.5x00.5Iteration 2/14/20180.52Iteration 53-1.51.5Iteration 43-21x11.52-2-1.5-1-0.500.511.52xIntroduction to Data Mining, 2nd Edition-2-1.5-1-0.500.511.52x56
Problems with Selecting Initial Points If there are K ‘real’ clusters then the chance of selectingone centroid from each cluster is small.–Chance is relatively small when K is large–If clusters are the same size, n, then–For example, if K 10, then probability 10!/1010 0.00036–Sometimes the initial centroids will readjust themselves in‘right’ way, and sometimes they don’t–Consider an example of five pairs of clusters02/14/2018Introduction to Data Mining, 2nd Edition57
810 Clusters Example6420246Starting with two initial centroids in one cluster of each pair of clusters02/14/2018Introduction to Data Mining, 2nd Edition58
10 Clusters ExampleIteration 28664422yyIteration 61020Iteration 48yyIteration 3515x8010152005x10xStarting with two initial centroids in one cluster of each pair of clusters02/14/2018Introduction to Data Mining, 2nd Edition59
10 Clusters ExampleStarting with some pairs of clusters having three initial centroids, while otherhave only one.02/14/20185Introduction to Data Mining, 2nd Edition10156020
10 Clusters ExampleIteration 28664422yyIteration ting with some pairs of clusters having three initial centroids, while other have only one.02/14/2018Introduction to Data Mining, 2nd Edition61
Solutions to Initial Centroids Problem Multiple runs– Helps, but probability is not on your side Sample and use hierarchical clustering to determineinitial centroidsSelect more than k initial centroids and then select amongthese initial centroids– Select most widely separated PostprocessingGenerate a larger number of clusters and then perform ahierarchical clusteringBisecting K-means– Not as susceptible to initialization issues02/14/2018Introduction to Data Mining, 2nd Edition62
Updating Centers Incrementally In the basic K-means algorithm, centroids areupdated after all points are assigned to a centroid An alternative is to update the centroids aftereach assignment (incremental approach)–––––Each assignment updates zero or two centroidsMore expensiveIntroduces an order dependencyNever get an empty clusterCan use “weights” to change the impact02/14/2018Introduction to Data Mining, 2nd Edition63
Bisecting K-means Bisecting K-means algorithm–Variant of K-means that can produce a partitional or ahierarchical clusteringCLUTO: iew02/14/2018Introduction to Data Mining, 2nd Edition64
Bisecting K-means Example02/14/2018Introduction to Data Mining, 2nd Edition65
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2nd Edition by Tan, Steinbach, Karpatne, Kumar . Three fundamental clustering algorithms Methods. 02/14/2018 Introduction to Data Mining, 2nd Edition 35 Clustering Algorithms