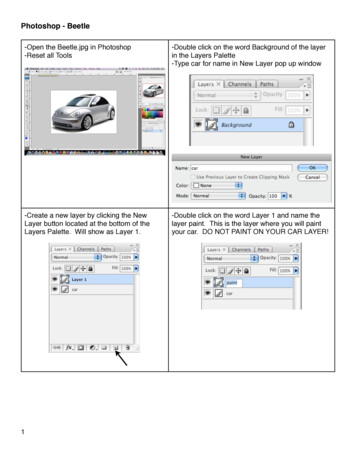
Transcription
Machine Learning:Multi Layer PerceptronsProf. Dr. Martin RiedmillerAlbert-Ludwigs-University FreiburgAG Maschinelles LernenMachine Learning: Multi Layer Perceptrons – p.1/61
Outline multi layer perceptrons (MLP) learning MLPs function minimization: gradient descend & related methodsMachine Learning: Multi Layer Perceptrons – p.2/61
Neural networks single neurons are not able to solve complex tasks (e.g. restricted to linearcalculations) creating networks by hand is too expensive; we want to learn from data nonlinear features also have to be generated by hand; tessalations becomeintractable for larger dimensionsMachine Learning: Multi Layer Perceptrons – p.3/61
Neural networks single neurons are not able to solve complex tasks (e.g. restricted to linearcalculations) creating networks by hand is too expensive; we want to learn from data nonlinear features also have to be generated by hand; tessalations becomeintractable for larger dimensions we want to have a generic model that can adapt to some training data basic idea: multi layer perceptron (Werbos 1974, Rumelhart, McClelland, Hinton1986),also named feed forward networksMachine Learning: Multi Layer Perceptrons – p.3/61
Neurons in a multi layer perceptron standard perceptrons calculate adiscontinuous function: x 7 fstep (w0 hw, xi)Machine Learning: Multi Layer Perceptrons – p.4/61
Neurons in a multi layer perceptron standard perceptrons calculate adiscontinuous function: x 7 fstep (w0 hw, xi)10.80.60.4 due to technical reasons, neurons inMLPs calculate a smoothed variantof this:0.20 8 6 4 202468 x 7 flog (w0 hw, xi)with1flog (z) 1 e zflog is called logistic functionMachine Learning: Multi Layer Perceptrons – p.4/61
Neurons in a multi layer perceptron standard perceptrons calculate a1discontinuous function:0.80.6 x 7 fstep (w0 hw, xi)0.4 due to technical reasons, neurons inMLPs calculate a smoothed variantof this: x 7 flog (w0 hw, xi)with1flog (z) 1 e zflog is called logistic function0.20 8 6 4 202468 properties: monotonically increasing limz 1 limz 0 flog (z) 1 flog ( z) continuous, differentiableMachine Learning: Multi Layer Perceptrons – p.4/61
Multi layer perceptrons A multi layer perceptrons (MLP) is a finite acyclic graph. The nodes areneurons with logistic activation.x1ΣΣ.Σx2ΣΣ.ΣΣ.xn.Σ.Σ.Σ neurons of i-th layer serve as input features for neurons of i 1th layer very complex functions can be calculated combining many neuronsMachine Learning: Multi Layer Perceptrons – p.5/61
Multi layer perceptrons(cont.) multi layer perceptrons, more formally:A MLP is a finite directed acyclic graph. nodes that are no target of any connection are called input neurons. AMLP that should be applied to input patterns of dimension n must have ninput neurons, one for each dimension. Input neurons are typicallyenumerated as neuron 1, neuron 2, neuron 3, . nodes that are no source of any connection are called output neurons. AMLP can have more than one output neuron. The number of outputneurons depends on the way the target values (desired values) of thetraining patterns are described. all nodes that are neither input neurons nor output neurons are calledhidden neurons. since the graph is acyclic, all neurons can be organized in layers, with theset of input layers being the first layer.Machine Learning: Multi Layer Perceptrons – p.6/61
Multi layer perceptrons(cont.) connections that hop over several layers are called shortcut most MLPs have a connection structure with connections from all neurons ofone layer to all neurons of the next layer without shortcuts all neurons are enumerated Succ(i ) is the set of all neurons j for which a connection i j exists Pred (i ) is the set of all neurons j for which a connection j i exists all connections are weighted with a real number. The weight of the connectioni j is named wji all hidden and output neurons have a bias weight. The bias weight of neuron iis named wi0Machine Learning: Multi Layer Perceptrons – p.7/61
Multi layer perceptrons(cont.) variables for calculation: hidden and output neurons have some variable net i (“network input”) all neurons have some variable ai (“activation”/“output”)Machine Learning: Multi Layer Perceptrons – p.8/61
Multi layer perceptrons(cont.) variables for calculation: hidden and output neurons have some variable net i (“network input”) all neurons have some variable ai (“activation”/“output”) applying a pattern x (x1 , . . . , xn )T to the MLP: for each input neuron the respective element of the input pattern ispresented, i.e. ai xiMachine Learning: Multi Layer Perceptrons – p.8/61
Multi layer perceptrons(cont.) variables for calculation: hidden and output neurons have some variable net i (“network input”) all neurons have some variable ai (“activation”/“output”) applying a pattern x (x1 , . . . , xn )T to the MLP: for each input neuron the respective element of the input pattern ispresented, i.e. ai xi for all hidden and output neurons i:after the values aj have been calculated for all predecessorsj Pred (i ), calculate net i and ai as:Xnet i wi0 (wij aj )j Pred(i)ai flog (net i )Machine Learning: Multi Layer Perceptrons – p.8/61
Multi layer perceptrons(cont.) variables for calculation: hidden and output neurons have some variable net i (“network input”) all neurons have some variable ai (“activation”/“output”) applying a pattern x (x1 , . . . , xn )T to the MLP: for each input neuron the respective element of the input pattern ispresented, i.e. ai xi for all hidden and output neurons i:after the values aj have been calculated for all predecessorsj Pred (i ), calculate net i and ai as:Xnet i wi0 (wij aj )j Pred(i)ai flog (net i ) the network output is given by the ai of the output neuronsMachine Learning: Multi Layer Perceptrons – p.8/61
Multi layer perceptrons(cont.) illustration:Σ1Σ2ΣΣΣΣΣΣ apply pattern x (x1 , x2 )TMachine Learning: Multi Layer Perceptrons – p.9/61
Multi layer perceptrons(cont.) illustration:Σ12ΣΣΣΣΣΣΣ apply pattern x (x1 , x2 )T calculate activation of input neurons: ai xiMachine Learning: Multi Layer Perceptrons – p.9/61
Multi layer perceptrons(cont.) illustration:Σ12ΣΣΣΣΣΣΣ apply pattern x (x1 , x2 )T calculate activation of input neurons: ai xi propagate forward the activations:Machine Learning: Multi Layer Perceptrons – p.9/61
Multi layer perceptrons(cont.) illustration:Σ12ΣΣΣΣΣΣΣ apply pattern x (x1 , x2 )T calculate activation of input neurons: ai xi propagate forward the activations: stepMachine Learning: Multi Layer Perceptrons – p.9/61
Multi layer perceptrons(cont.) illustration:Σ12ΣΣΣΣΣΣΣ apply pattern x (x1 , x2 )T calculate activation of input neurons: ai xi propagate forward the activations: step byMachine Learning: Multi Layer Perceptrons – p.9/61
Multi layer perceptrons(cont.) illustration:Σ12ΣΣΣΣΣΣΣ apply pattern x (x1 , x2 )T calculate activation of input neurons: ai xi propagate forward the activations: step by stepMachine Learning: Multi Layer Perceptrons – p.9/61
Multi layer perceptrons(cont.) illustration:Σ1Σ2 apply pattern xΣΣΣΣΣΣ (x1 , x2 )Tcalculate activation of input neurons: ai xipropagate forward the activations: step by stepread the network output from both output neuronsMachine Learning: Multi Layer Perceptrons – p.9/61
Multi layer perceptrons(cont.) algorithm (forward pass):Require: pattern x, MLP, enumeration of all neurons in topological orderEnsure: calculate output of MLP1: for all input neurons i do2: set ai xi3: end for4: for all hidden and output neurons i in topological order doP5: set net i wi0 j Pred(i) wij aj6:7:8:9:10:11:set ai flog (net i )end forfor all output neurons i doassemble ai in output vector yend forreturn yMachine Learning: Multi Layer Perceptrons – p.10/61
Multi layer perceptrons(cont.) variant:2Neurons with logistic activation canonly output values between 0 and 1.To enable output in a wider range ofreal number variants are used:1.510.5flog (2x)0 0.5 1 neurons with tanh activationfunction:tanh(x)linear activation 1.5 2 3 2 10123 net ieneti eai tanh(net i ) net net iei e neurons with linear activation:ai net iMachine Learning: Multi Layer Perceptrons – p.11/61
Multi layer perceptrons(cont.) variant:2Neurons with logistic activation canonly output values between 0 and 1.To enable output in a wider range ofreal number variants are used:1.510.5flog (2x)0 0.5 1 neurons with tanh activationfunction: neurons with linear activation:ai net ilinear activation 1.5 2 3 net ieneti eai tanh(net i ) net net iei etanh(x) 2 10123 the calculation of the networkoutput is similar to the case oflogistic activation except therelationship between net i and aiis different. the activation function is a localproperty of each neuron.Machine Learning: Multi Layer Perceptrons – p.11/61
Multi layer perceptrons(cont.) typical network topologies: for regression: output neurons with linear activation for classification: output neurons with logistic/tanh activation all hidden neurons with logistic activation layered layout:input layer – first hidden layer – second hidden layer – . – output layerwith connection from each neuron in layer i with each neuron in layeri 1, no shortcut connectionsMachine Learning: Multi Layer Perceptrons – p.12/61
Multi layer perceptrons(cont.) typical network topologies: for regression: output neurons with linear activation for classification: output neurons with logistic/tanh activation all hidden neurons with logistic activation layered layout:input layer – first hidden layer – second hidden layer – . – output layerwith connection from each neuron in layer i with each neuron in layeri 1, no shortcut connections Lemma:Any boolean function can be realized by a MLP with one hidden layer. Anybounded continuous function can be approximated with arbitrary precision bya MLP with one hidden layer.Proof: was given by Cybenko (1989). Idea: partition input space in smallcellsMachine Learning: Multi Layer Perceptrons – p.12/61
MLP Training given training data: D {( x(1) , d (1) ), . . . , ( x(p) , d (p) )} where d (i) is thedesired output (real number for regression, class label 0 or 1 forclassification) given topology of a MLP task: adapt weights of the MLPMachine Learning: Multi Layer Perceptrons – p.13/61
MLP Training(cont.) idea: minimize an error termp1X y( x(i) ; w) d (i) 2E(w; D) 2 i 1with y( x; w) : network output for input pattern x and weight vector w ,22 u squared length of vector u: u Pdim( u)j 1(uj )2Machine Learning: Multi Layer Perceptrons – p.14/61
MLP Training(cont.) idea: minimize an error termp1X y( x(i) ; w) d (i) 2E(w; D) 2 i 1with y( x; w) : network output for input pattern x and weight vector w ,22 u squared length of vector u: u Pdim( u)j 1(uj )2 learning means: calculating weights for which the error becomes minimalminimize E(w; D)w Machine Learning: Multi Layer Perceptrons – p.14/61
MLP Training(cont.) idea: minimize an error termp1X y( x(i) ; w) d (i) 2E(w; D) 2 i 1with y( x; w) : network output for input pattern x and weight vector w ,22 u squared length of vector u: u Pdim( u)j 1(uj )2 learning means: calculating weights for which the error becomes minimalminimize E(w; D)w interpret E just as a mathematical function depending on w and forget aboutits semantics, then we are faced with a problem of mathematical optimizationMachine Learning: Multi Layer Perceptrons – p.14/61
Optimization theory discusses mathematical problems of the form:minimize f ( u) u u can be any vector of suitable size. But which one solves this task and howcan we calculate it?Machine Learning: Multi Layer Perceptrons – p.15/61
Optimization theory discusses mathematical problems of the form:minimize f ( u) u u can be any vector of suitable size. But which one solves this task and howcan we calculate it? some simplifications:here we consider only functions f which are continuous and differentiableyyxnon continuous function(disrupted)yxcontinuous, non differentiablefunction (folded)xdifferentiable function(smooth)Machine Learning: Multi Layer Perceptrons – p.15/61
Optimization theory(cont.) A global minimum u is a point soythat:f ( u ) f ( u)for all u. A local minimum u is a point so thatexist r 0 withf ( u ) f ( u)for all points u with u u xglobal rlocalminimaMachine Learning: Multi Layer Perceptrons – p.16/61
Optimization theory(cont.) analytical way to find a minimum:For a local minimum u , the gradient of f becomes zero: f ( u ) 0 uifor all iHence, calculating all partial derivatives and looking for zeros is a good idea(c.f. linear regression)Machine Learning: Multi Layer Perceptrons – p.17/61
Optimization theory(cont.) analytical way to find a minimum:For a local minimum u , the gradient of f becomes zero: f ( u ) 0 uifor all iHence, calculating all partial derivatives and looking for zeros is a good idea(c.f. linear regression) fbut: there are also other points for which uiequations is often not possible 0, and resolving theseMachine Learning: Multi Layer Perceptrons – p.17/61
Optimization theory(cont.) numerical way to find a minimum, searching:assume we are starting at a point u.Which is the best direction to search for apoint v with f ( v ) f ( u) ? uMachine Learning: Multi Layer Perceptrons – p.18/61
Optimization theory(cont.) numerical way to find a minimum, searching:assume we are starting at a point u.Which is the best direction to search for apoint v with f ( v ) f ( u) ?slope is negative (descending),go right! uMachine Learning: Multi Layer Perceptrons – p.18/61
Optimization theory(cont.) numerical way to find a minimum, searching:assume we are starting at a point u.Which is the best direction to search for apoint v with f ( v ) f ( u) ? uMachine Learning: Multi Layer Perceptrons – p.18/61
Optimization theory(cont.) numerical way to find a minimum, searching:assume we are starting at a point u.Which is the best direction to search for apoint v with f ( v ) f ( u) ?slope is positive (ascending),go left! uMachine Learning: Multi Layer Perceptrons – p.18/61
Optimization theory(cont.) numerical way to find a minimum, searching:assume we are starting at a point u.Which is the best direction to search for apoint v with f ( v ) f ( u) ?Which is the best stepwidth? uMachine Learning: Multi Layer Perceptrons – p.18/61
Optimization theory(cont.) numerical way to find a minimum, searching:assume we are starting at a point u.Which is the best direction to search for apoint v with f ( v ) f ( u) ?Which is the best stepwidth?slope is small, small step! uMachine Learning: Multi Layer Perceptrons – p.18/61
Optimization theory(cont.) numerical way to find a minimum, searching:assume we are starting at a point u.Which is the best direction to search for apoint v with f ( v ) f ( u) ?Which is the best stepwidth? uMachine Learning: Multi Layer Perceptrons – p.18/61
Optimization theory(cont.) numerical way to find a minimum, searching:assume we are starting at a point u.Which is the best direction to search for apoint v with f ( v ) f ( u) ?Which is the best stepwidth?slope is large, large step! uMachine Learning: Multi Layer Perceptrons – p.18/61
Optimization theory(cont.) numerical way to find a minimum, searching:assume we are starting at a point u.Which is the best direction to search for apoint v with f ( v ) f ( u) ?Which is the best stepwidth? general principle: fv i ui ǫ uiǫ 0 is called learning rate uMachine Learning: Multi Layer Perceptrons – p.18/61
Gradient descent Gradient descent approach:Require: mathematical function f , learning rate ǫ 0Ensure: returned vector is close to a local minimum of f1: choose an initial point u2: while grad f ( u) not close to 0 do3: u u ǫ · grad f ( u)4: end while5: return u open questions: how to choose initial u how to choose ǫ does this algorithm really converge?Machine Learning: Multi Layer Perceptrons – p.19/61
Gradient descent(cont.) choice of ǫMachine Learning: Multi Layer Perceptrons – p.20/61
Gradient descent(cont.) choice of ǫ1. case small ǫ: convergenceMachine Learning: Multi Layer Perceptrons – p.20/61
Gradient descent(cont.) choice of ǫ2. case very small ǫ: convergence, but it maytake very longMachine Learning: Multi Layer Perceptrons – p.20/61
Gradient descent(cont.) choice of ǫ3. case medium size ǫ: convergenceMachine Learning: Multi Layer Perceptrons – p.20/61
Gradient descent(cont.) choice of ǫ4. case large ǫ: divergenceMachine Learning: Multi Layer Perceptrons – p.20/61
Gradient descent(cont.) choice of ǫ is crucial. Only small ǫ guaranteeconvergence. for small ǫ, learning may take very long depends on the scaling of f : an optimallearning rate for f may lead to divergencefor 2 · fMachine Learning: Multi Layer Perceptrons – p.20/61
Gradient descent(cont.) some more problems with gradient descent: flat spots and steep valleys:need larger ǫ in u to jump over theuninteresting flat area but need smaller ǫin v to meet the minimum u vMachine Learning: Multi Layer Perceptrons – p.21/61
Gradient descent(cont.) some more problems with gradient descent: flat spots and steep valleys:need larger ǫ in u to jump over theuninteresting flat area but need smaller ǫin v to meet the minimum u v zig-zagging:in higher dimensions:for all dimensionsǫ is not appropriateMachine Learning: Multi Layer Perceptrons – p.21/61
Gradient descent(cont.) conclusion:pure gradient descent is a nice theoretical framework but of limited power inpractice. Finding the right ǫ is annoying. Approaching the minimum is timeconsuming.Machine Learning: Multi Layer Perceptrons – p.22/61
Gradient descent(cont.) conclusion:pure gradient descent is a nice theoretical framework but of limited power inpractice. Finding the right ǫ is annoying. Approaching the minimum is timeconsuming. heuristics to overcome problems of gradient descent: gradient descent with momentum individual lerning rates for each dimension adaptive learning rates decoupling steplength from partial derivatesMachine Learning: Multi Layer Perceptrons – p.22/61
Gradient descent(cont.) gradient descent with momentumidea: make updates smoother by carrying forward the latest update.1: choose an initial point u 0 (stepwidth) while grad f ( u) not close to 0 do ǫ · grad f ( u) µ u u 2: set3:4:5:6: end while7: return uµ 0, µ 1 is an additional parameter that has to be adjusted by hand.For µ 0 we get vanilla gradient descent.Machine Learning: Multi Layer Perceptrons – p.23/61
Gradient descent(cont.) advantages of momentum: smoothes zig-zagging accelerates learning at flat spots slows down when signs of partialderivatives change disadavantage: additional parameter µ may cause additional zig-zaggingMachine Learning: Multi Layer Perceptrons – p.24/61
Gradient descent(cont.) advantages of momentum: smoothes zig-zagging accelerates learning at flat spots slows down when signs of partialderivatives change disadavantage: additional parameter µ may cause additional zig-zaggingvanilla gradient descentMachine Learning: Multi Layer Perceptrons – p.24/61
Gradient descent(cont.) advantages of momentum: smoothes zig-zagging accelerates learning at flat spots slows down when signs of partialderivatives change disadavantage: additional parameter µ may cause additional zig-zagginggradient descent withmomentumMachine Learning: Multi Layer Perceptrons – p.24/61
Gradient descent(cont.) advantages of momentum: smoothes zig-zagging accelerates learning at flat spots slows down when signs of partialderivatives change disadavantage: additional parameter µ may cause additional zig-zagginggradient descent withstrong momentumMachine Learning: Multi Layer Perceptrons – p.24/61
Gradient descent(cont.) advantages of momentum: smoothes zig-zagging accelerates learning at flat spots slows down when signs of partialderivatives change disadavantage: additional parameter µ may cause additional zig-zaggingvanilla gradient descentMachine Learning: Multi Layer Perceptrons – p.24/61
Gradient descent(cont.) advantages of momentum: smoothes zig-zagging accelerates learning at flat spots slows down when signs of partialderivatives change disadavantage: additional parameter µ may cause additional zig-zagginggradient descent withmomentumMachine Learning: Multi Layer Perceptrons – p.24/61
Gradient descent(cont.) adaptive learning rateidea: make learning rate individual for each dimension and adaptive if signs of partial derivative change, reduce learning rate if signs of partial derivative don’t change, increase learning rate algorithm: Super-SAB (Tollenare 1990)Machine Learning: Multi Layer Perceptrons – p.25/61
Gradient descent(cont.)1: choose an initial point uη 1, η 1 are2: set initial learning rate ǫadditional parameters thathave to be adjusted byhand. For η η 1we get vanilla gradientdescent.3: set former gradient γ 08: grad f ( u) not close to 0 docalculate gradient g grad f ( u)for all dimensionsi do η ǫi if gi · γi 0ǫi η ǫi if gi · γi 0 ǫotherwiseiui ui ǫi gi9:end for10: γ g4: while5:6:7:11: end while12: return uMachine Learning: Multi Layer Perceptrons – p.26/61
Gradient descent(cont.) advantages of Super-SAB and relatedapproaches: decouples learning rates of differentdimensions accelerates learning at flat spots slows down when signs of partialderivatives change disadavantages: steplength still depends on partialderivativesMachine Learning: Multi Layer Perceptrons – p.27/61
Gradient descent(cont.) advantages of Super-SAB and relatedapproaches: decouples learning rates of differentdimensions accelerates learning at flat spots slows down when signs of partialderivatives change disadavantages: steplength still depends on partialderivativesvanilla gradient descentMachine Learning: Multi Layer Perceptrons – p.27/61
Gradient descent(cont.) advantages of Super-SAB and relatedapproaches: decouples learning rates of differentdimensions accelerates learning at flat spots slows down when signs of partialderivatives change disadavantages: steplength still depends on partialderivativesSuperSABMachine Learning: Multi Layer Perceptrons – p.27/61
Gradient descent(cont.) advantages of Super-SAB and relatedapproaches: decouples learning rates of differentdimensions accelerates learning at flat spots slows down when signs of partialderivatives change disadavantages: steplength still depends on partialderivativesvanilla gradient descentMachine Learning: Multi Layer Perceptrons – p.27/61
Gradient descent(cont.) advantages of Super-SAB and relatedapproaches: decouples learning rates of differentdimensions accelerates learning at flat spots slows down when signs of partialderivatives change disadavantages: steplength still depends on partialderivativesSuperSABMachine Learning: Multi Layer Perceptrons – p.27/61
Gradient descent(cont.) make steplength independent of partial derivativesidea: use explicit steplength parameters, one for each dimension if signs of partial derivative change, reduce steplength if signs of partial derivative don’t change, increase steplegth algorithm: RProp (Riedmiller&Braun, 1993)Machine Learning: Multi Layer Perceptrons – p.28/61
Gradient descent(cont.)1: choose an initial point uη 1, η 1 are 2: set initial steplength additional parameters thathave to be adjusted byhand. For MLPs, goodheuristics exist forparameter settings:η 1.2, η 0.5,initial i 0.13: set former gradient γ 04: while grad f ( u) not close to 0 do5: calculate gradient g grad f ( u)6: for all dimensionsi do 7:8: η i if gi · γi 0 i η i if gi · γi 0 otherwisei ui i if gi 0ui ui i if gi 0 uotherwisei9: end for10: γ g11: end while12: return uMachine Learning: Multi Layer Perceptrons – p.29/61
Gradient descent(cont.) advantages of Rprop decouples learning rates of differentdimensions accelerates learning at flat spots slows down when signs of partialderivatives change independent of gradient lengthMachine Learning: Multi Layer Perceptrons – p.30/61
Gradient descent(cont.) advantages of Rprop decouples learning rates of differentdimensions accelerates learning at flat spots slows down when signs of partialderivatives change independent of gradient lengthvanilla gradient descentMachine Learning: Multi Layer Perceptrons – p.30/61
Gradient descent(cont.) advantages of Rprop decouples learning rates of differentdimensions accelerates learning at flat spots slows down when signs of partialderivatives change independent of gradient lengthRpropMachine Learning: Multi Layer Perceptrons – p.30/61
Gradient descent(cont.) advantages of Rprop decouples learning rates of differentdimensions accelerates learning at flat spots slows down when signs of partialderivatives change independent of gradient lengthvanilla gradient descentMachine Learning: Multi Layer Perceptrons – p.30/61
Gradient descent(cont.) advantages of Rprop decouples learning rates of differentdimensions accelerates learning at flat spots slows down when signs of partialderivatives change independent of gradient lengthRpropMachine Learning: Multi Layer Perceptrons – p.30/61
Beyond gradient descent Newton Quickprop line searchMachine Learning: Multi Layer Perceptrons – p.31/61
Beyond gradient descent(cont.) Newton’s method:approximate f by a second-order Taylor polynomial:1 T f ( u ) f ( u) grad f ( u) · H( u) 2with H( u) the Hessian of f at u, the matrix of second order partialderivatives.Machine Learning: Multi Layer Perceptrons – p.32/61
Beyond gradient descent(cont.) Newton’s method:approximate f by a second-order Taylor polynomial:1 T f ( u ) f ( u) grad f ( u) · H( u) 2with H( u) the Hessian of f at u, the matrix of second order partialderivatives. :Zeroing the gradient of approximation with respect to 0 (grad f ( u))T H( u) Hence: (H( u)) 1 (grad f ( u))T Machine Learning: Multi Layer Perceptrons – p.32/61
Beyond gradient descent(cont.) Newton’s method:approximate f by a second-order Taylor polynomial:1 T f ( u ) f ( u) grad f ( u) · H( u) 2with H( u) the Hessian of f at u, the matrix of second order partialderivatives. :Zeroing the gradient of approximation with respect to 0 (grad f ( u))T H( u) Hence: (H( u)) 1 (grad f ( u))T advantages: no learning rate, no parameters, quick convergence disadvantages: calculation of H and H 1 very time consuming in highdimensional spacesMachine Learning: Multi Layer Perceptrons – p.32/61
Beyond gradient descent(cont.) Quickprop (Fahlmann, 1988) like Newton’s method, but replaces H by a diagonal matrix containingonly the diagonal entries of H . hence, calculating the inverse is simplified replaces second order derivatives by approximations (difference ratios)Machine Learning: Multi Layer Perceptrons – p.33/61
Beyond gradient descent(cont.) Quickprop (Fahlmann, 1988) like Newton’s method, but replaces H by a diagonal matrix containingonly the diagonal entries of H . hence, calculating the inverse is simplified replaces second order derivatives by approximations (difference ratios) update rule: witwhere git gitt 1t w(w: tii )t 1gi gi grad f at time t. advantages: no learning rate, no parameters, quick convergence in manycases disadvantages: sometimes unstableMachine Learning: Multi Layer Perceptrons – p.33/61
Beyond gradient descent(cont.) line search algorithms:gradtwo nested loops: outer loop: determine serachdirection from gradientsearch line inner loop: determine minimizingpoint on the line defined by currentsearch position and searchdirection inner loop can be realized by any problem: time consuming forhigh-dimensional spacesminimization algorithm forone-dimensional tasks advantage: inner loop algorithm maybe more complex algorithm, e.g.NewtonMachine Learning: Multi Layer Perceptrons – p.34/61
Beyond gradient descent(cont.) line search algorithms:gradtwo nested loops: outer loop: determine serachdirection from gradientsearch line inner loop: determine minimizingpoint on the line defined by currentsearch position and searchdirection problem: time consuming forhigh-dimensional spaces inner loop can be realized by anyminimization algorithm forone-dimensional tasks advantage: inner loop algorithm maybe more complex algorithm, e.g.NewtonMachine Learning: Multi Layer Perceptrons – p.34/61
Beyond gradient descent(cont.) line search algorithms:two nested loops: outer loop: determine serachsearch linegraddirection from gradient inner loop: determine minimizingpoint on the line defined by currentsearch position and searchdirection problem: time consuming forhigh-dimensional spaces inner loop can be realized by anyminimization algorithm forone-dimensional tasks advantage: inner loop algorithm maybe more complex algorithm, e.g.NewtonMachine Learning: Multi Layer Perceptrons – p.34/61
Summary: optimization theory several algorithms to solve problems of the form:minimize f ( u) u gradient descent gives the main idea Rprop plays major role in context of MLPs dozens of variants and alternatives existMachine Learning: Multi Layer Perceptrons – p.35/61
Back to MLP Training training an MLP means solving:minimize E(w; D)w for give
Neural networks single neurons are not able to solve complex tasks (e.g. restricted to linear calculations) creating networks by hand is too expensive; we want to learn from data nonlinear features also have to be generated by hand; tessalations become intractable for larger dimensions Machine Learning: Multi Layer Perceptrons - p.3/61