Transcription
doi:10.1145/1941487 . 1 9 4 1 5 0 7Energy efficiency is the new fundamentallimiter of processor performance,way beyond numbers of processors.by Shekhar Borkar and Andrew A. ChienThe FutureofMicroprocessorsMic rop ro ce s s o r s — sin gl e -c h ip c ompu t e r s —arethe building blocks of the information world. Theirperformance has grown 1,000-fold over the past 20years, driven by transistor speed and energy scaling, aswell as by microarchitecture advances that exploitedthe transistor density gains from Moore’s Law. In thenext two decades, diminishing transistor-speed scaling and practical energy limits create new challenges forcontinued performance scaling. Asa result, the frequency of operationswill increase slowly, with energy thekey limiter of performance, forcingdesigns to use large-scale parallelism, heterogeneous cores, and accelerators to achieve performance andenergy efficiency. Software-hardwarepartnership to achieve efficient dataorchestration is increasingly critical inthe drive toward energy-proportionalcomputing.Our aim here is to reflect and project the macro trends shaping the future of microprocessors and sketch inbroad strokes where processor designis going. We enumerate key researchchallenges and suggest promisingresearch directions. Since dramaticchanges are coming, we also seek toinspire the research community to in-vent new ideas and solutions addresshow to sustain computing’s exponential improvement.Microprocessors (see Figure 1) wereinvented in 1971,28 but it’s difficult today to believe any of the early inventorscould have conceived their extraordinary evolution in structure and useover the past 40 years. Microprocessorstoday not only involve complex micro-key insights M oore’s Law continues but demandsradical changes in architecture andsoftware. A rchitectures will go beyondhomogeneous parallelism, embraceheterogeneity, and exploit the bountyof transistors to incorporateapplication-customized hardware. S oftware must increase parallelismand exploit heterogeneous andapplication-customized hardwareto deliver performance growth.may 2 0 1 1 vo l . 5 4 n o. 5 c o m m u n icat io n s o f t he acm67
contributed articlesarchitectures and multiple executionengines (cores) but have grown to include all sorts of additional functions,including floating-point units, caches,memory controllers, and media-processing engines. However, the defining characteristics of a microprocessorremain—a single semiconductor chipembodying the primary computation(data transformation) engine in a computing system.Because our own greatest accessand insight involves Intel designs anddata, our graphs and estimates drawheavily on them. In some cases, theymay not be representative of the entireindustry but certainly represent a largefraction. Such a forthright view, solidlygrounded, best supports our goals forthis article.20 Years of ExponentialPerformance GainsFor the past 20 years, rapid growth inmicroprocessor performance has beenenabled by three key technology drivers—transistor-speed scaling, core microarchitecture techniques, and cachememories—discussed in turn in thefollowing sections:Transistor-speed scaling. The MOStransistor has been the workhorse fordecades, scaling in performance bynearly five orders of magnitude andproviding the foundation for today’sunprecedented compute performance.The basic recipe for technology scalingwas laid down by Robert N. Dennard ofIBM17 in the early 1970s and followedfor the past three decades. The scaling recipe calls for reducing transistorFigure 1. Evolution of Intel microprocessors 1971–2009.Intel 4004, 19711 core, no cache23K transistorsIntel 8088, 19781 core, no cache29K transistorsIntel Mehalem-EX, 20098 cores, 24MB cache2.3B transistorsFigure 2. Architecture advances and energy efficiency.Die AreaInteger Performance (X)FP Performance (X)Int Performance/Watt (X)386 to 4864486 to PentiumIncrease (X)3Pentium to P6P6 to Pentium 42Pentium 4to Core10On-die cache,pipelined68Super-scalarcommun ic ations of th e acmOOO-Speculative May 2 0 1 1 vol . 5 4 no. 5Deep pipelineBack to non-deeppipelinedimensions by 30% every generation(two years) and keeping electric fieldsconstant everywhere in the transistor to maintain reliability. This mightsound simple but is increasingly difficult to continue for reasons discussedlater. Classical transistor scaling provided three major benefits that madepossible rapid growth in compute performance.First, the transistor dimensions arescaled by 30% (0.7x), their area shrinks50%, doubling the transistor densityevery technology generation—the fundamental reason behind Moore’s Law.Second, as the transistor is scaled, itsperformance increases by about 40%(0.7x delay reduction, or 1.4x frequency increase), providing higher systemperformance. Third, to keep the electric field constant, supply voltage is reduced by 30%, reducing energy by 65%,or power (at 1.4x frequency) by 50%(active power CV2f). Putting it all together, in every technology generationtransistor integration doubles, circuitsare 40% faster, and system power consumption (with twice as many transistors) stays the same. This serendipitous scaling (almost too good to betrue) enabled three-orders-of-magnitude increase in microprocessor performance over the past 20 years. Chiparchitects exploited transistor densityto create complex architectures andtransistor speed to increase frequency,achieving it all within a reasonablepower and energy envelope.Coremicroarchitecturetechniques. Advanced microarchitectureshave deployed the abundance of transistor-integration capacity, employinga dizzying array of techniques, including pipelining, branch prediction,out-of-order execution, and speculation, to deliver ever-increasing performance. Figure 2 outlines advances inmicroarchitecture, showing increasesin die area and performance and energy efficiency (performance/watt),all normalized in the same processtechnology. It uses characteristics ofIntel microprocessors (such as 386,486, Pentium, Pentium Pro, and Pentium 4), with performance measuredby benchmark SpecInt (92, 95, and2000 representing the current benchmark for the era) at each data point.It compares each microarchitectureadvance with a design without the ad-
contributed articlescaused designers to forego many ofthese microarchitecture techniques.As Pollack’s Rule broadly capturesarea, power, and performance tradeoffs from several generations of microarchitecture, we use it as a ruleof thumb to estimate single-threadperformance in various scenariosthroughout this article.Cache memory architecture. Dynamic memory technology (DRAM)has also advanced dramatically withMoore’s Law over the past 40 years butwith different characteristics. For example, memory density has doublednearly every two years, while performance has improved more slowly (seeFigure 4a). This slower improvementin cycle time has produced a memorybottleneck that could reduce a system’s overall performance. Figure 4boutlines the increasing speed disparity, growing from 10s to 100s of processor clock cycles per memory access. Ithas lately flattened out due to the flattening of processor clock frequency.Unaddressed, the memory-latency gapwould have eliminated and could stilleliminate most of the benefits of processor improvement.The reason for slow improvementof DRAM speed is practical, not technological. It’s a misconception thatDRAM technology based on capacitorstorage is inherently slower; rather, thememory organization is optimized fordensity and lower cost, making it slower. The DRAM market has demandedlarge capacity at minimum cost overspeed, depending on small and fastcaches on the microprocessor die toemulate high-performance memoryby providing the necessary bandwidthand low latency based on data locality.The emergence of sophisticated, yeteffective, memory hierarchies allowedDRAM to emphasize density and costover speed. At first, processors used asingle level of cache, but, as processorspeed increased, two to three levels ofcache hierarchies were introduced tospan the growing speed gap betweenFigure 3. Increased performance vs. area in the same process technology followsPollack’s Rule.10.0Integer Performance (X)Performance Sqrt(Area)386 to 486Pentium to P6486 to Pentium1.0P6 to Pentium 4Pentium 4 to CoreSlope 0.50.10.11.010.0Area (X)Figure 4. DRAM density and performance, 1980–2010.10,0001,000CPU Clocks/DRAM Latency100,000DRAM DensityCPURelativevance (such as introducing an on-diecache by comparing 486 to 386 in 1μtechnology and superscalar microarchitecture of Pentium in 0.7μ technology with 486).This data shows that on-die cachesand pipeline architectures used transistors well, providing a significantperformance boost without compromising energy efficiency. In this era,superscalar, and out-of-order architectures provided sizable performancebenefits at a cost in energy efficiency.Of these architectures, deep-pipelined design seems to have deliveredthe lowest performance increase forthe same area and power increase asout-of-order and speculative design,incurring the greatest cost in energyefficiency. The term “deep pipelinedarchitecture” describes deeper pipeline, as well as other circuit and microarchitectural techniques (such astrace cache and self-resetting dominologic) employed to achieve even higher frequency. Evident from the data isthat reverting to a non-deep pipelinereclaimed energy efficiency by dropping these expensive and inefficienttechniques.When transistor performance increases frequency of operation, theperformance of a well-tuned systemgenerally increases, with frequencysubject to the performance limits ofother parts of the system. Historically,microarchitecture techniques exploiting the growth in available transistorshave delivered performance increasesempirically described by Pollack’sRule,32 whereby performance increases (when not limited by other partsof the system) as the square root ofthe number of transistors or area ofa processor (see Figure 3). Accordingto Pollack’s Rule, each new technology generation doubles the numberof transistors on a chip, enabling anew microarchitecture that delivers a40% performance increase. The fastertransistors provide an additional 40%performance (increased frequency),almost doubling overall performancewithin the same power envelope (perscaling theory). In practice, however,implementing a new microarchitecture every generation is difficult, somicroarchitecture gains are typicallyless. In recent microprocessors, the increasing drive for energy efficiency has1,000Speed100GAP10DRAM may 2 0 1 1 vo l . 5 4 n o. 5 c o m m u n icat io n s o f t he acm69
contributed articlesprocessor and memory.33,37 In thesehierarchies, the lowest-level cacheswere small but fast enough to matchthe processor’s needs in terms of highbandwidth and low latency; higher levels of the cache hierarchy were thenoptimized for size and speed.Figure 5 outlines the evolution ofon-die caches over the past two decades, plotting cache capacity (a) andpercentage of die area (b) for Intelmicroprocessors. At first, cache sizesincreased slowly, with decreasing diearea devoted to cache, and most of theavailable transistor budget was devoted to core microarchitecture advances.During this period, processors wereprobably cache-starved. As energy became a concern, increasing cache sizefor performance has proven more energy efficient than additional core-microarchitecture techniques requiringenergy-intensive logic. For this reason,more and more transistor budget anddie area are allocated in caches.The transistor-scaling-and-micro-Figure 5. Evolution of on-die caches.60%1,000On-die cache %of total die areaOn-die cache 5nm1u0.5u0.25u(a)0.13u65nm(b)Figure 6. Performance increase separated into transistor speed and microarchitectureperformance.10,000Floating-Point PerformanceTransistor Performance1,000Relative1,000Relative10,000Integer PerformanceTransistor Performance100Table 1. New technology scalingchallenges.10110.5u0.18uThe Next 20 YearsMicroprocessor technology has delivered three-orders-of-magnitude performance improvement over the pasttwo decades, so continuing this trajectory would require at least 30x performance increase by 2020. Micropro-100101.5uarchitecture-improvement cycle hasbeen sustained for more than twodecades, delivering 1,000-fold performance improvement. How long will itcontinue? To better understand andpredict future performance, we decouple performance gain due to transistorspeed and microarchitecture by comparing the same microarchitectureon different process technologies andnew microarchitectures with the previous ones, then compound the performance gain.Figure 6 divides the cumulative1,000-fold Intel microprocessor performance increase over the past twodecades into performance delivered bytransistor speed (frequency) and due tomicroarchitecture. Almost two-ordersof-magnitude of this performance increase is due to transistor speed alone,now leveling off due to the numerouschallenges described in the ased transistor scaling benefits:Despite continuing miniaturization, littleperformance improvement and littlereduction in switching energy (decreasingperformance benefits of scaling) [ITRS].Flat total energy budget: packagepower and mobile/embedded computingdrives energy-efficiency requirements.Figure 7. Unconstrained evolution of a microprocessor results in excessive powerconsumption.Table 2. Ongoing technology scaling.500Unconstrained Evolution 100mm2 DiePower (Watts)400Increasing transistor density (in areaand volume) and count: throughcontinued feature scaling, processinnovations, and packaging innovations.300200Need for increasing locality andreduced bandwidth per operation:as performance of the microprocessorincreases, and the data sets forapplications continue to grow.1000200270commun ic ations of th e ac m20062010 May 2 0 1 1 vol . 5 4 no. 520142008
contributed articlesDeath of90/10 Optimization,Rise of10 10 OptimizationTraditional wisdom suggests investing maximum transistors in the 90% case, withthe goal of using precious transistors to increase single-thread performance that canbe applied broadly. In the new scaling regime typified by slow transistor performanceand energy improvement, it often makes no sense to add transistors to a single coreas energy efficiency suffers. Using additional transistors to build more cores producesa limited benefit—increased performance for applications with thread parallelism.In this world, 90/10 optimization no longer applies. Instead, optimizing with anaccelerator for a 10% case, then another for a different 10% case, then another 10%case can often produce a system with better overall energy efficiency and performance.We call this “10 10 optimization,”14 as the goal is to attack performance as a set of10% optimization opportunities—a different way of thinking about transistor cost,operating the chip with 10% of the transistors active—90% inactive, but a different 10%at each point in time.Historically, transistors on a chip were expensive due to the associated designeffort, validation and testing, and ultimately manufacturing cost. But 20 generationsof Moore’s Law and advances in design and validation have shifted the balance.Building systems where the 10% of the transistors that can operate within the energybudget are configured optimally (an accelerator well-suited to the application) maywell be the right solution. The choice of 10 cases is illustrative, and a 5 5, 7 7, 10 10,or 12 12 architecture might be appropriate for a particular design.er envelope is around 65 watts, andthe die size is around 100mm2. Figure8 outlines a simple analysis for 45nmprocess technology node; the x-axis isthe number of logic transistors integrated on the die, and the two y-axesare the amount of cache that would fitand the power the die would consume.As the number of logic transistors onthe die increases (x-axis), the size of thecache decreases, and power dissipation increases. This analysis assumesaverage activity factor for logic andcache observed in today’s microprocessors. If the die integrates no logic atall, then the entire die could be populated with about 16MB of cache andconsume less than 10 watts of power,since caches consume less power thanlogic (Case A). On the other hand, if itintegrates no cache at all, then it couldintegrate 75 million transistors for logic, consuming almost 90 watts of power (Case B). For 65 watts, the die couldintegrate 50 million transistors forlogic and about 6MB of cache (Case C).Figure 8. Transistor integration capacity at a fixed power envelope.2008, 45nm, 100mm218100Case A, 16MB of Cache16natiosipiser D8014Pow12Cac60heSizCase C50MT Logic6MB Cachee10840Cache (MB)Total Power (Watts)cessor-performance scaling faces newchallenges (see Table 1) precludinguse of energy-inefficient microarchitecture innovations developed over thepast two decades. Further, chip architects must face these challenges withan ongoing industry expectation of a30x performance increase in the nextdecade and 1,000x increase by 2030(see Table 2).As the transistor scales, supplyvoltage scales down, and the threshold voltage of the transistor (whenthe transistor starts conducting) alsoscales down. But the transistor is nota perfect switch, leaking some smallamount of current when turned off,increasing exponentially with reduction in the threshold voltage. In addition, the exponentially increasingtransistor-integration capacity exacerbates the effect; as a result, a substantial portion of power consumption isdue to leakage. To keep leakage undercontrol, the threshold voltage cannotbe lowered further and, indeed, mustincrease, reducing transistor performance.10As transistors have reached atomicdimensions, lithography and variability pose further scaling challenges, affecting supply-voltage scaling.11 Withlimited supply-voltage scaling, energyand power reduction is limited, adversely affecting further integrationof transistors. Therefore, transistorintegration capacity will continue withscaling, though with limited performance and power benefit. The challenge for chip architects is to use thisintegration capacity to continue to improve performance.Package power/total energy consumption limits number of logic transistors. If chip architects simply addmore cores as transistor-integrationcapacity becomes available and operate the chips at the highest frequency the transistors and designs canachieve, then the power consumptionof the chips would be prohibitive (seeFigure 7). Chip architects must limitfrequency and number of cores to keeppower within reasonable bounds, butdoing so severely limits improvementin microprocessor performance.Consider the transistor-integrationcapacity affordable in a given powerenvelope for reasonable die size. Forregular desktop applications the pow-64202Case A, 0 Logic, 8W000204060Case B80Logic Transistors (Millions)may 2 0 1 1 vo l . 5 4 n o. 5 c o m m u n ic ati o n s o f t he acm71
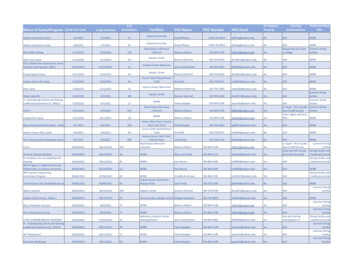
contributed articlesThis design point matches the dualcore microprocessor on 45nm technology (Core2 Duo), integrating two coresof 25 million transistors each and 6MBof cache in a die area of about 100mm2.If this analysis is performed for future technologies, assuming (our bestestimates) modest frequency increase15% per generation, 5% reduction insupply voltage, and 25% reduction ofFigure 9. Three scenarios for integrating 150-million logic transistors into cores.5 MTLarge-Core25 MT23Large-Core25MT25 MT3456233020Large-Core HomogeneousSmall-Core HomogeneousSmall-Core roughput6Small-corethroughputPollack’s Rule(5/25)0.5 0.45Small-corethroughputPollack’s Rule(5/25)0.5 ure 10. A system-on-a-chip from Texas Instruments.Display SubsystemC64x DSPand videoaccelerators(3525/3530 only)ARMCortexA8CPULCDControllerVideoEnc10-bit DAC10-bit DACCamera I/F2D/3D Graphics(3515/3530 only)ImagePipeParallel I/FL3/L4 InterconnectPeripheralsConnectivityUSB 2.0 HSOTG ControllerSystemTimersGP x12WDT x2USB HostController x2Program/Data StorageSerial InterfacesMcBSP x5McSPI x472I2C x3UART x2UART w/IRDAcommunicat ions of th e ac mHDQ/1-wireSDRCGPMC May 2 0 1 1 vo l . 5 4 no. 5MMC/SD/SDIOx3capacitance, then the results will beas they appear in Table 1. Note thatover the next 10 years we expect increased total transistor count, following Moore’s Law, but logic transistorsincrease by only 3x and cache transistors increase more than 10x. Applying Pollack’s Rule, a single processorcore with 150 million transistors willprovide only about 2.5x microarchitecture performance improvement overtoday’s 25-million-transistor core,well shy of our 30x goal, while 80MB ofcache is probably more than enoughfor the cores (see Table 3).The reality of a finite (essentiallyfixed) energy budget for a microprocessor must produce a qualitative shift inhow chip architects think about architecture and implementation. First, energy-efficiency is a key metric for thesedesigns. Second, energy-proportionalcomputing must be the ultimate goalfor both hardware architecture andsoftware-application design. Whilethis ambition is noted in macro-scalecomputing in large-scale data centers,5 the idea of micro-scale energyproportional computing in microprocessors is even more challenging. Formicroprocessors operating within afinite energy budget, energy efficiencycorresponds directly to higher performance, so the quest for extreme energyefficiency is the ultimate driver for performance.In the following sections, we outline key challenges and sketch potential approaches. In many cases, thechallenges are well known and thesubject of significant research overmany years. In all cases, they remaincritical but daunting for the future ofmicroprocessor performance:Organizing the logic: Multiple coresand customization. The historic measure of microprocessor capability isthe single-thread performance of atraditional core. Many researchershave observed that single-thread performance has already leveled off, withonly modest increases expected in thecoming decades. Multiple cores andcustomization will be the major drivers for future microprocessor performance (total chip performance). Multiple cores can increase computationalthroughput (such as a 1x–4x increasecould result from four cores), and customization can reduce execution la-
contributed articlesTable 3. Extrapolated transistorintegration capacity in a fixed 6201410025201815080Cache MBtency. Clearly, both techniques—multiple cores and customization—canimprove energy efficiency, the newfundamental limiter to capability.Choices in multiple cores. Multiplecores increase computational throughput by exploiting Moore’s Law to replicate cores. If the software has noparallelism, there is no performancebenefit. However, if there is parallelism, the computation can be spreadacross multiple cores, increasing overall computational performance (andreducing latency). Extensive researchon how to organize such systems datesto the 1970s.29,39Industry has widely adopted a multicore approach, sparking many questions about number of cores and size/power of each core and how they coordinate.6,36 But if we employ 25-million-transistor cores (circa 2008), the150-million-logic-transistorbudgetexpected in 2018 gives 6x potentialthroughput improvement (2x fromfrequency and 3x from increased logic transistors), well short of our 30xgoal. To go further, chip architectsmust consider more radical optionsof smaller cores in greater numbers,along with innovative ways to coordinate them.Looking to achieve this vision,consider three potential approachesto deploying the feasible 150 millionlogic transistors, as in Table 1. In Figure 9, option (a) is six large cores (goodsingle-thread performance, total potential throughput of six); option (b) is30 smaller cores (lower single-threadperformance, total potential throughput of 13); and option (c) is a hybridapproach (good single-thread performance for low parallelism, total potential throughput of 11).Many more variations are possibleon this spectrum of core size and num-ber of cores, and the related choicesin a multicore processor with uniforminstruction set but heterogeneous implementation are an important partof increasing performance within thetransistor budget and energy envelope.Choices in hardware customization.Customization includes fixed-functionaccelerators (such as media codecs,cryptography engines, and compositing engines), programmable accelerators, and even dynamically customizable logic (such as FPGAs and otherdynamic structures). In general, customization increases computationalperformance by exploiting hardwiredor customized computation units, customized wiring/interconnect for datamovement, and reduced instructionsequence overheads at some cost ingenerality. In addition, the level of parallelism in hardware can be customized to match the precise needs of thecomputation; computation benefitsfrom hardware customization onlywhen it matches the specialized hardware structures. In some cases, unitshardwired to a particular data representation or computational algorithmcan achieve 50x–500x greater energyefficiency than a general-purpose register organization. Two studies21,22 of amedia encoder and TCP offload engineillustrate the large energy-efficiencyimprovement that is possible.Due to battery capacity and heatdissipation limits, for many yearsenergy has been the fundamentallimiter for computational capabil-ity in smartphone system-on-a-chip(SoC). As outlined in Figure 10, suchan SoC might include as many as 10to 20 accelerators to achieve a superior balance of energy efficiency andperformance. This example could alsoinclude graphics, media, image, andcryptography accelerators, as well assupport for radio and digital signalprocessing. As one might imagine,one of these blocks could be a dynamically programmable element (such asan FPGA or a software-programmableprocessor).Another customization approachconstrains the types of parallelismthat can be executed efficiently, enabling a simpler core, coordination,and memory structures; for example,many CPUs increase energy efficiencyby restricting memory access structureand control flexibility in single-instruction, multiple-data or vector (SIMD)structures,1,2 while GPUs encourageprograms to express structured setsof threads that can be aligned and executed efficiently.26,30 This alignmentreduces parallel coordination andmemory-access costs, enabling use oflarge numbers of cores and high peakperformance when applications canbe formulated with a compatible parallel structure. Several microprocessormanufacturers have announced futuremainstream products that integrateCPUs and GPUs.Customization for greater energyor computational efficiency is a longstanding technique, but broad adop-Table 4. Logic organization challenges, trends, directions.ChallengeNear-TermLong-TermIntegration andmemory modelI/O-based interaction, shared memoryspaces, explicit coherence managementIntelligent, automatic data movementamong heterogeneous cores, managedby software-hardware partnershipSoftwaretransparencyExplicit partition and mapping,virtualization, application managementHardware-based state adaptationand software-hardware partnershipfor managementLower-powercoresHeterogeneous cores, vector extensions, Deeper, explicit storage hierarchy withinthe core; integrated computation inand GPU-like techniques to reduceregistersinstruction- and data-movement costEnergymanagementHardware dynamic voltage scalingand intelligent adaptive management,software core selection and schedulingPredictive core scheduling and selectionto optimize energy efficiency andminimize data movementAcceleratorvarietyIncreasing variety, library-basedencapsulation (such as DX and OpenGL)for specific domainsConverged accelerators in a fewapplication categories and increasingopen programmability for theacceleratorsmay 2 0 1 1 vo l . 5 4 n o. 5 c o m m u n ic ati o n s o f t he acm73
contributed articlestion has been slowed by continuedimprovement in microprocessor single-thread performance. Developers ofsoftware applications had little incentive to customize for accelerators thatmight be available on only a fraction ofthe machines in the field and for whichthe performance advantage mightsoon be overtaken by advances in thetraditional microprocessor. With slowing improvement in single-thread performance, this landscape has changedsignificantly, and for many applications, accelerators may be the onlyFigure 11. On-die interconnect delay and energy (45nm).10,000Wire Energy110(pJ)Wire n-die network energy per bit1001.5pJ/Bit1,000Delay (ps)1,0002200.5u0.18u65nm22nm8nmOn-die interconnect length (mm)(a)(b)Figure 12. Hybrid switching for network-on-a-chip.CCCBusCCCCCCCCCCBusCBus to connecta clusterCCCBusRCCCCCCCRBusCCSecond-level bus to connectclusters (hierarchy of busses)CCBusCCBusRBusCBusCCRBusCCCSecond-level router-basednetwork (hierarchy of networks)Table 5. Data movement challenges, trends, ncreased parallelismHeterogeneous parallelism andcustomization, hardware/runtimeplacement, migration, adaptationfor locality and load balanceData Movement/ More complex, more exposed hierarchies; New memory abstractions andmechanisms for efficient verticalLocalitynew abstractions for control overdata locality management with lowmovement and “snooping”programming effort and energyResilienceMore aggressive energy reduction;compensated by recovery for resilienceRadical new memory technologies(new physics) and resilience techniquesEnergyProportionalCommunica
Figure 4a). This slower improvement in cycle time has produced a memory bottleneck that could reduce a sys-tem’s overall performance. Figure 4b outlines the increasing speed dispar-ity, growing from 10s to 100s of proces-sor clock cycles per memory access. It has lately flattened