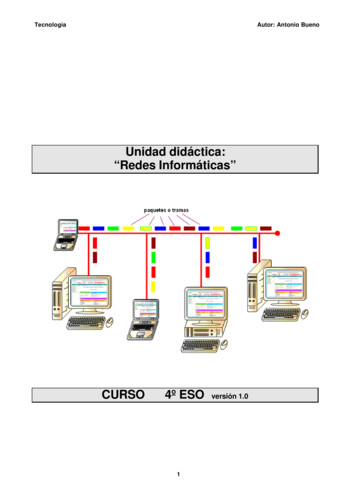
Transcription
Redes para ClustersRedes para Clusters Redes Ethernet Redes Ethernet– Ethernet– Fast Ethernet– Gigabit Ethernet Myrinet InfiniBand– Ethernet LAN introducida en 1982 y más utilizada en los años90 Ancho de banda a 10 Mbits/seg No muy adecuada para clusters debido a su bajo anchode banda Basada en el concepto de dominios de colisión– Fast Ethernet LAN introducida en 1994 y más utilizada actualmente Ancho de banda a 100 Mbits/seg Mediante el uso de conmutadores y hubs se puedendefinir varios dominios de colisión separados El S.O. interviene en la introducción y extracción delos mensajes, vía interrupciones La latencia aplicación-aplicación depende del driver ydel API– TCP/IP aprox. 150µs– U-Net, MVIA aprox. 50 µs– Gigabit Ethernet LAN introducida en 1998 Ancho de banda a 1 Gbits/seg Basado en conmutadores punto-a-punto rápidos1
Redes para Clusters Myrinet– Red diseñada por Myricom– Válida para LAN y SAN (System-Area Network)– Ancho de banda de 1,28 Gbits/seg, con conmutaciónwormholeRedes para Clusters InfiniBand– Nuevo estándar que define un nuevo sistema deinterconexión a alta velocidad punto a punto basado enswitches.– Diseñado para conectar los nodos de procesado y losdispositivos de E/S, para formar una red de área desistema (SAN)– Rompe con el modelo de E/S basada en transaccioneslocales a través de buses, y apuesta por un modelobasado en el paso remoto de mensajes a través decanales.– Arquitectura independiente del sistema operativo y delprocesador del equipo.– Soportada por un consorcio de las empresas másimportantes en el campo: IBM, Sun, HP-Compaq,Intel, Microsoft, Dell, etc.– La responsabilidad se reparte entre el procesador delnodo y LANai LANai es un dispositivo de comunicación programableque ofrece un interfaz a Myrinet. LANai se encarga de las interrupciones originadas porlos mensajes– DMA directa entre cola FIFO y memoria NIC, y entrememoria NIC y memoria del nodo La memoria NIC puede asignarse al espacio lógico delos procesos La latencia aplicación-aplicación es de aprox. 9µs.Arquitectura de InfiniBand2
Redes para ClustersEjemplo de Cluster: Google (i) Funcionamiento ante una petición– Características de la red Infiniband No hay bus E/S Todos los sistemas se interconectan medianteadaptadores HCA o TCA La red permite múltiples transferencias de datospaquetizados Permite RDMA (Remote Memory Access Read orWrite) Implica modificaciones en el software del sistema– Selección del servidor Google que atenderá la petición(balanceo de carga basado en DNS entre varios clusters)– Búsqueda en un índice invertido que empareja cada palabrade búsqueda con una lista de identificadores de documentos– Los servidores de índice intersectan las diferentes listas ycalculan un valor de relevancia para cada documentoreferenciado (establece el orden de los resultados)– Los servidores de documentos extraen información básica(título, URL, sumario, etc.) de los documentos a partir de losidentificadores anteriores (ya ordenados) Características– Paralelismo multinivel A nivel de petición: Se resuelven en paralelo múltiplespeticiones independientes. A nivel de término de búsqueda: Cada término de búsquedapuede chequearse en paralelo en los servidores de índice. A nivel de índice: El índice de los documentos está dividido enpiezas que comprenden una selección elegida aleatoriamente dedocumentos.– Principios del diseño de Google Fiabilidad hardware: Existe redundancia a diferentes niveles,como alimentación eléctrica, discos magnéticos en array(RAID), componentes de alta calidad, etc. Alta disponibilidad y servicio: Mediante la replicación masivade los servicios críticos Preferencia en precio/rendimiento frente a rendimientopico: Múltiples servidores hardware de bajo coste configuradosen cluster. PCs convencionales: Uso masivo de PCs convencionalesfrente a hardware especializado en alto rendimiento.3
Ejemplo de Cluster: Google (ii)Ejemplo de Cluster: Google (iii)(Datos de Diciembre de 2000) Se realizan alrededor de 1.000 consultas por segundo Cada página Web es visitada una vez al mes paraactualizar las tablas de índices El objetivo es que la búsqueda tarde menos de 0.5 seg(incluido los retrasos de red) Utiliza más de 6000 procesadores y 12.000 discos (1petabyte) Por fiabilidad dispone de tres sites redundantes: dos enSilicon Valley y uno en Virginia (sólo en uno se rastrea laWeb para generar las tablas de índices) Para la conexión a Internet se utiliza una conexión OC48(2488Mbits/seg) Dispone de conexiones extra (OC12, 622Mbits/seg) parahacer el sistema más robusto Dispone de dos switchs (Foundry, 128 x 1Gbit/s Ethernet)por fiabilidad Un site dispone de 40 racks y cada rack contiene 80 PCs Cada PC está compuesto por:– Un procesador desde un Pentium Celeron (533Mhz) a unPentium III (800MHz)– Dos discos duros entre 40 y 80Gb– 256Mb de SDRAM– Sistema operativo Linux Red Hat Cada rack tiene dos líneas Ethernet de 1Gbit/s conectadasa ambos switches4
Programación y aplicaciones Herramientas para generar programas paralelos Modos de progamación– Paralelismo deMultiple-Data)datosProgramación y aplicaciones(SPMD,Single-Program Los códigos que se ejecutan en paralelo se obtienencompilando el mismo programa. Cada copia trabaja con un conjunto de datos distintos ysobre un procesador diferente. Es el modo de programación más utilizado Recomendable en sistemas masivamente paralelos– Difícil encontrar cientos de unidades de código distintas Grado de paralelismo muy alto, pero no está presente entodas las aplicaciones.– Paralelismo de tareas o funciones (MPMD, MultiplePrograms Multiple-Data) Los códigos que se ejecutan en paralelo se obtienencompilando programas independientes. La aplicación a ejecutar se divide en unidadesindependientes. Cada unidad trabaja con un conjunto de datos y seasigna a un procesador distinto. Inherente en todas las aplicaciones. Generalmente tiene un grado de paralelismo bajo.– Bibliotecas de funciones para la programación El programador utiliza un lenguaje secuencial (C o Fortran),para escribir el cuerpo de los procesos y las hebras. También,usando el lenguaje secuencial, distribuye las tareas entre losprocesos. El programador, utilizando las funciones de la biblioteca:– Crea y gestiona los procesos.– Implementa la comunicación y sincronización.– Incluso puede elegir la distribución de los procesos entre losprocesadores (siempre que lo permitan las funciones). Ventajas– Los programadores están familiarizados con los lenguajessecuenciales.– Las bibliotecas están disponibles para todos los sistemas paralelos.– Las bibliotecas están más cercanas al hardware y dan alprogramador un control a bajo nivel– Podemos usar las bibliotecas tanto para programar con hebrascomo con procesos Ejemplos– MPI, PVM, OpenMP y Pthread.– Lenguajes paralelos y directivas del compilador Utilizamos lenguajes paralelos o lenguajes secuenciales condirectivas del compilador, para generar los programas paralelos. Los lenguajes paralelos utilizan:– Construcciones propias del lenguaje, como p.e. FORALL para elparalelismo de datos. Estas construcciones, además de distribuir lacarga de trabajo, pueden crear y terminar procesos.– Directivas del compilador para especificar las máquinas virtualesde los procesadores, o como se asignan los datos a dichasmáquinas.– Funciones de biblioteca, que implementan en paralelo algunasoperaciones típicas. Ventajas: Facilidad de escritura y claridad. Son más cortos.– Compiladores paralelos Un compilador, a partir de un código secuencial, extraeautomáticamente el paralelismo a nivel de bucle (de datos) y anivel de función (de tareas, en esto no es muy eficiente).5
Programación y aplicaciones Modos de programación– Paso de mensajes La comunicación entre procesos se produce mediantemensajes de envío y recepción de datos. Las transmisiones pueden ser síncronas o asíncronas Normalmente se usa el envío no bloqueante y larecepción bloqueante. PVM, MPI.– Variables compartidas La comunicación entre procesos se realiza mediante elacceso a variables compartidas. Lenguajes de programación: Ada 95 o Java. Bibliotecas de funciones: Pthread (POSIX-Thread) uOpenMP. Lenguaje secuencial directivas: OpenMP.– Paralelismo de datos Se aprovecha el paralelismo inherente a aplicaciones enlas que los datos se organizan en estructuras (vectores omatrices). El compilador paraleliza las construcciones delprogramador.– Bucles, operandos tipo vector o matriz, distribución de lacarga entre los elementos de procesado. C*, lenguaje muy ligado a procesadores matriciales Fortran 90 (basado en Fortran 77) permite usaroperaciones sobre vectores y matrices. HPF (ampliación de Fortran 90).– Comunicaciones implícitas [A(I) A(I-1)], paralelizarbucles (FORALL), distribuir los datos entre losprocesadores (PROCESSORS, DISTRIBUTE), funcionesde reducción (a partir de un vector obtenemos un escalar),funciones de reordenación de datos en un vector, etc.Programación y aplicaciones Estructuras de programas paralelosParalelismo idealMaestro-EsclavoSegmentaciónDivide y vencerás Fases de la programación paralela– Descomposición funcional: Identificar las funcionesque debe realizar la aplicación y las relaciones entreellas.– Partición Distribución de las funciones en procesos y esquema decomunicación entre procesos. Objetivo: maximizar el grado de paralelismo yminimizar la comunicación entre procesos.– Localización Los procesos se asignan a procesadores del sistema Objetivo: ajustar los patrones de comunicación a latopología del sistema.– Escribir el código paralelo– Escalado: Determina el tamaño óptimo del sistema enfunción de algún parámetro de entrada.6
Programación y aplicaciones Ejemplo 1: Paralelizar el cálculo delnúmero π.– Objetivo: Calcular el número π medianteintegración numérica, teniendo en cuentaque la integral en el intervalo [0,1] de laderivada del arco tangente de x es π/4.1 1 x2 1π π1 arctg ( x) 10 0arctg (1) 044 1 x2arctg (0) 0 arctg ′( x) – Vamos a basarnos en una versiónsecuencial. En ella se aproxima el área encada subintervalo utilizando rectángulosen los que la altura es el valor de laderivada del arco tangente en el puntomedio.Programación y aplicacionesVersión secuencialGrafo de dependenciasentre tareasMain (int argc, char **argv){double ancho, x, sum;int intervalos, i;intervalos atoi(argv[1]);ancho 1.0/(double) intervalos;for (i 0; i intervalos;i ){x (i 0.5)*ancho;sum sum 4.0/(1.0 x*x);}sum* ancho; }– Asignamos tareas a procesos o hebras. Suponemos que tenemos un cluster Beowulf,con 8 PCs. En cada procesador se ejecutará un proceso. La carga de trabajo se distribuirá por igualentre los procesadores. Realizaremos una planificación estática de lastareas.– Escribimos el código paralelo usandoMPI (paso de mensajes). Utilizaremos parelelismo de datos. Partiendo de la versión secuencial obtenemosel código SPMD paralelo.7
Programación y aplicacionesVersión SPMD paraleloIncluir libreríasDeclarar variables#include mpi.h Main (int argc, char **argv){double ancho, x, sum,tsum 0;int intervalos, i,nproc,iproc;if(MPI Init(&argc, &argv) MPI SUCCESS) exit(1);MPI Comm size(MPI COMM WORLD, &nproc);MPI Comm rank(MPI COMM WORLD, &iproc);Crear procesosintervalos atoi(argv[1]);ancho 1.0/(double) intervalos;for (i iproc; i intervalos;i nproc){x (i 0.5)*ancho;sum sum 4.0/(1.0 x*x);}sum* ancho;MPI Reduce(&sum,&tsum,1,MPI DOUBLE,MPI SUM,0,MPI COMM WORLD);MPI erminar procesos}Programación y aplicaciones Crear y terminar procesos– MPI Init(): Crea el proceso que lo ejecuta dentrodel mundo MPI, es decir, dentro del grupo deprocesos denominado MPI COMM WORLD. Unavez que se ejecuta esta función se pueden utilizar elresto de funciones MPI.– MPI Finalice(): Se debe llamar antes de que unproceso creado en MPI acabe su ejecución.– MPI Comm size(MPI COMM WORLD,&nproc): Con esta función se pregunta a MPI elnúmero de procesos creados en el grupoMPI COMM WORLD, se devuelve en nproc.– MPI Comm rank(MPI COMM WORLD,&iproc): Con esta función se devuelve al procesosu identificador, iproc, dentro del grupo. Asignar tareas a procesos y localizar paralelismo.– Se reparten las iteraciones del bucle entre losdiferentes procesos MPI de forma explícita. Seutiliza un turno rotatorio. Comunicación y sincronización.– Los procesos se comunican y sincronizan parasumar las áreas parciales calculadas por losprocesos.– Usamos MPI Reduce. Esta es una operacióncooperativa realizada entre todos los miembros delcomunicador y se obtiene un único resultado final.– Los procesos envían al proceso 0 el contenido de suvariable local sum, los contenidos de sum se sumany se guardan en el proceso 0 en la variable tsum.8
Programación y aplicaciones– Escribimos el código paralelo usando OpenMP condirectivas (variables compartidas).Versión OpenMP variables compartidasIncluir libreríasDeclarar variablesy constantes#include omp.h #define NUM THREADS 4 Crear y terminar hebras– omp set num threads(): Función OpenMP que modificaen tiempo de ejecución el número de hebras que se puedenutilizar en paralelo; para ello sobrescribe el contenido de lavariable OMP NUM THREADS, que contiene dichonúmero.– #pragma omp parallel: esta directiva crea un conjunto dehebras; el número será el valor que tengaOMP NUM THREADS menos uno, ya que tambiéninterviene en el cálculo el padre. El código de las hebrascreadas es el que sigue a esta directiva, puede ser unaúnica sentencia o varias.Main (int argc, char **argv){Register double ancho, x;int intervalos, i;intervalos atoi(argv[1]);ancho 1.0/(double) intervalos;omp set num threads(NUM THREADS)#pragma omp parallel#pragma omp for reduction( ronizarAsignar/localizarfor (i 0; i intervalos;i ){x (i 0.5)*ancho;sum sum 4.0/(1.0 x*x);}sum* ancho;}Programación y aplicacionesprivate(x) Asignar tareas a procesos y localizar paralelismo.– #pragma omp for: La directiva for identifica o localiza unconjunto de trabajo compartido iterativo paralelizable yespecifica que se distribuyan las iteraciones del bucle forentre las hebras del grupo cuya creación se ha especificadocon una directiva parallel. Esta directiva obliga a quetodas las hebras se sincronicen al terminar el ciclo.» schedule(dynamic): Utilizamos una distribucióndinámica de las hebras.» private(x): Hace que cada hebra tenga una copiaprivada de la variable x, es decir, esta variable noserá compartida.» reduction( :sum): Hace que cada hebra utilicedentro del ciclo una variable sum local, y que, unavez terminada la ejecución de todas las hebras, sesumen todas las variables locales sum y el resultadopase a una variable compartida sum. Comunicación y sincronización.– Utilizamos una variable compartida llamada sum paraalmacenar el resultado final definida por reduction( :sum).9
- Bibliotecas de funciones para la programación El programador utiliza un lenguaje secuencial (C o Fortran), para escribir el cuerpo de los procesos y las hebras. También, usando el lenguaje secuencial, distribuye las tareas entre los procesos. El programador, utilizando las funciones de la biblioteca: - Crea y gestiona los procesos.