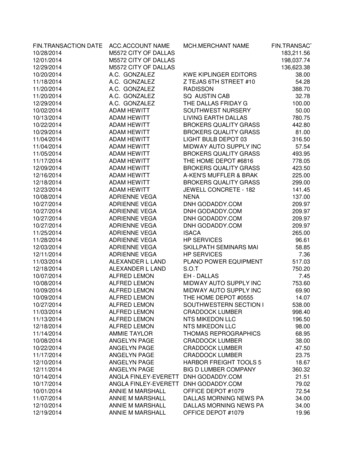
Transcription
GridDB and Cassandra Performance and Scalability.A YCSB Performance Comparison on Microsoft Azure.October 31, 2016Revision 1.5.0
Table of ContentsExecutive Summary . 3Introduction . 3Environment . 4Azure Configuration . 4Software Versions . 4Software Configuration . 4GridDB . 4Cassandra . 4General . 5Test Methodology . 6Test Design . 6Methodology . 6Collection and Aggregation . 7Benchmark Results . 8Load. 8Workload A . 10Workload B . 12Workload C. 14Workload D . 16Workload F . 18Long Term Workload A . 21Tabular Results . 22Throughput with Small Data Set (4M Records Per Node) . 22Latency with Small Data Set (4M Records Per node) -- 1 Node . 23Latency with Small Data Set (4M Records Per node) -- 8 Nodes . 23Latency with Small Data Set (4M Records Per node) -- 16 Nodes. 24Latency with Small Data Set (4M Records Per node) -- 32 Nodes. 24Throughput with Large Data Set (12M Records Per Node) . 25Latency with Large Data Set (12M Records Per Node) -- 1 Node . 26Latency with Large Data Set (12M Records Per Node) -- 8 Nodes. 26Latency with Large Data Set (12M Records Per Node) -- 16 Nodes . 27Latency with Large Data Set (12M Records Per Node) -- 32 Nodes . 27Conclusion . 28Appendices . 29Configuration Files . 29gs node.json . 29gs cluster.json . 30cassandra.yaml . 30Cassandra Schema . 32Page 2
Executive SummaryWith the introduction of Toshiba’s GridDB NoSQL database, Fixstars performed benchmarksusing YCSB on Microsoft Azure to compare GridDB with one of the leading NoSQL databases:Apache Cassandra. These benchmarks were performed on 1 through 32 node clusters withdifferent total database sizes. These varied conditions hoped to show how the differentdatabases compared across different workload parameters.The overall conclusions of the performance benchmarks are that GridDB outperformedCassandra in both throughput and latency, and that GridDB is truly scalable and capable ofconsistent performance in long-run operations.NOTE: As of version 4.5, GridDB Community Edition does not support clusteringIntroductionNoSQL databases were designed to overcome some of the limitations of relational databasesand to offer greater scalability, reliability, and flexibility over their predecessors. Withemerging technologies such as cloud and mobile computing, the Internet of Things, and everincreasing amounts of data being collected and processed, NoSQL databases are the firstchoice for today’s and tomorrow’s applications.GridDB is a distributed NoSQL database developed by Toshiba that can be operated as an inmemory database or with a hybrid composition. It is fully ACID-compliant (Atomicity,Consistency, Isolation, Durability) at the container level and has a rich set of features. It canalso be used as either a Key-Container or TimeSeries database.Cassandra is a free and open source distributed NoSQL database. Cassandra is considered tohave some of the best performance of the major NoSQL databases while maintaining highavailability and a decentralized design.The Yahoo! Cloud Serving Benchmark, or YCSB, is a modular benchmark for NoSQL or Keystore databases that is written in Java.Page 3
EnvironmentAzure ConfigurationThree resource groups were created, each with 65 Standard D2 instances in the West-USregion. The Standard D2 instances feature two Intel Xeon CPU E5-2673 cores running at2.40GHz, 7GB of memory, 1Gpbs networking, and a 100GB local SSD. The local SSD was usedto store the GridDB and Cassandra’s data files while a persistent page blob stored the OSdisk.Each instance was based on the OpenLogic Centos 6.5 Linux image. The first instancecontained a public IP address and acted as a headnode while up to 32 instances would be usedas NoSQL database servers and an equal number of instances ran YCSB clients.The headnode was responsible for starting the servers, executing the YCSB clients, collectingresource utilization statistics, and aggregating the results.Software VersionsGridDB version 3.0 CE was installed into the Azure nodes using RPM packages provided byToshiba Corporation.For Cassandra, version 3.4 was installed from Datastax’s community YUM repository.YCSB was cloned from its github repository on July 5, 2016. The Cassandra2 Database driverremained unmodified. Toshiba provided their YCSB GridDB driver in August 2016 and it wasmodified to use the Fixed List connection method instead of Multicast.Software ConfigurationGridDBFor the most part, GridDB used the default or recommended configuration. Experimentationconfirmed that these were the ideal values for the setup. Concurrency was set to 2 to matchthe number of cores, while checkMemoryLimit was set to 512MB and storeMemoryLimit wasset to 6144MB. This configuration allowed plenty of space to keep 4GB of records in memoryand allowed approximately 512MB for other system actions.GridDB used the fixed list method of communicating with other GridDB servers instead of themore typical multicast method because Azure and most other Cloud providers do not supportmulticast between instances.The only other change from the default values was setting storeBlockSize to 32KB from 64KB.CassandraAs many other benchmarks with Cassandra reported, write timeouts were a problem withCassandra. To address this, core workload insertion retry limit was increased to 10 from 0 inthe YCSB workload file and read request timout in ms was increased to 5 seconds whilewrite request timeout in ms, counter write request timeout in ms, andrange request timeout in ms were all increased to 10 seconds.Page 4
To reduce cluster start up times, n-1 seeds were used where n is the number of nodes. 1 and 4seeds were also experimented with but were deemed to have no impact on performance in asingle rack/datacenter environment.Concurrent readers, writers, and were all set to 32 as confirmed by experimentation.GeneralFor all systems, the maximum number of open files was increased to 64000 via limits.conf.Page 5
Test MethodologyTest DesignThe goal of the testing was to see how each database performed under a variety of conditionswhile maintaining similar parameters as other high profile NoSQL benchmarks.In earlier, smaller scale testing, it was discovered that thread counts between 32 and 192 allproduced similar results, but 128 threads was the most consistent. A thread count of 128 wastherefore used for all subsequent testing except for Cassandra loads which use 32 threads toprevent Timeout exceptions. Further research has shown that this is fairly common behaviorwith Cassandra and while the configuration can be modified, best performance is achievedwith fewer threads.It was determined that two data sets would be used, a small data set of 4M records per node,and a larger dataset that would store 12M records per node. Each record would consist of ten100 byte strings (1Kbyte per record), therefore the per node database size would be 4GB or12GB respectively. The small data set could fit entirely within memory, while 50% of the largedata set would need to be flushed from local memory stores or caches. The transactionalworkloads would each perform 10M operations per client and would have access to the entiredata set. This configuration would give Cassandra sufficient time for JVM warm up andensure that rows would be both in and out of cache.MethodologyDue to the inherent inconsistency of running a workload on shared cloud services, each seriesof tests were run three times in a different resource group and the results shown here are fromthe individual best throughput for each workload. This decision was made to minimizeperformance fluctuations caused by Azure as the benchmark’s goal was to evaluate GridDBand Cassandra, not Azure.Starting from a state where all instances are “deallocated”, the headnode would first start therequired number of instances. Once they are running, deploy configuration files, mount thelocal SSD, remove any existing database data files, and finally start GridDB or Cassandra viatheir initscript.Once the servers have finished starting, server statistics via gs stat for GridDB or nodetool forCassandra would be captured and stored for further analysis.YCSB load would be executed concurrently on all the client nodes with the appropriateinsertstart, insertcount, recordcount parameters. After the load completes, workloads are runin the following order according to the YCSB recommendation Core-Workloads): Workload A -- Update heavyWorkload B -- Mostly readsWorkload C -- Read onlyWorkload F -- Read, modify, writeWorkload D -- Read latestServer statistics are once again captured after each workload finishes.Page 6
Collection and AggregationAll YCSB output is captured for post processing and result compilation. Simple bash scriptsusing awk and grep were used to output a single test run per line in CSV format and werethen further processed in a spreadsheet.Page 7
Benchmark ResultsLoadOther Cassandra benchmark reports have reported difficulties in loading data into Cassandra— Fixstars encountered similar issues. Increasing concurrent writers from the recommendedsettings, extending timeouts by a factor of 10, and reducing the number of threads to 32corrected all TimeoutExceptions. For throughput, higher is better and for latency, lower isbetter.Load Throughput (4M records/node)400,000350,000Throughput 00100,00050,00000102030Number of NodesLoad Throughput (12M records/node)300,000250,000Throughput 000102030Number of NodesPage 8
Load Latency (4M Records/ Node)35Load Latency (ms)3025201510501 Node8 Node16 Node32 NodeLower is BetterGridDBCassandraLoad Latency (12M Records/ Node)4540Load Latency (ms)353025201510501 Node8 Node16 Node32 NodeLower is BetterGridDBCassandraPage 9
Workload AWorkload A is an update intensive workload. For throughput, higher is better and for latency,lower is better.Workload A Throughput (4M records/node)300,000250,000Throughput 000102030Number of NodesWorkload A Throughput (12M records/node)80,00070,000Throughput ,00010,00000102030Number of NodesPage 10
Workload A Latency (4M Records/Node)250Latency (ms)200150100500ReadUpdate1 NodeReadUpdate8 NodesReadUpdate16 NodesReadUpdate32 NodesLower is BetterGridDBCassandraWorkload A Latency (12M Records/ Node)300250Latency (ms)200150100500ReadUpdate1 NodeReadUpdate8 NodesReadUpdate16 NodesReadUpdate32 NodesLower is BetterGridDBCassandraPage 11
Workload BWorkload B contains 95% read operations and 5% write operations. For throughput, higher isbetter and for latency, lower is better.Workload B Throughput (4M records/node)600,000Throughput 00100,00000102030Number of NodesWorkload B Throughput (12M records/node)200,000180,000160,000Throughput 060,00040,00020,00000102030Number of NodesPage 12
Workload B Latency (4M Records/ Node)180160140Latency (ms)120100806040200ReadUpdateRead1 NodeUpdate8 NodesReadUpdate16 NodesReadUpdate32 NodesLower is BetterGridDBCassandraWorkload B Latency (12M Records/Node)250Latency (ms)200150100500ReadUpdate1 NodeReadUpdateRead8 NodesUpdate16 NodesReadUpdate32 NodesLower is BetterGridDBCassandraPage 13
Workload CWorkload C is only read operations. For throughput, higher is better and for latency, lower isbetter.Workload C Throughput (4M records/node)700,000600,000Throughput 00100,00000102030Number of NodesWorkload C Throughput (12M records/node)250,000Throughput 000102030Number of NodesPage 14
Workload C Latency (4M Records/Node)140120Latency (ms)1008060402001 Node8 Node16 Node32 NodeLower is BetterGridDBCassandraWorkload C Latency (12M Records/Node)250Latency (ms)2001501005001 Node8 Node16 Node32 NodeLower is BetterGridDBCassandraPage 15
Workload DWorkload D inserts new records and then reads those new records. For throughput, higher isbetter and for latency, lower is better.Workload D Throughput (4M records/node)900,000800,000Throughput ra300,000200,000100,00000102030Number of NodesWorkload D Throughput (12M records/node)350,000300,000Throughput 0050,00000102030Number of NodesPage 16
Workload D Latency (4M Records/Node)908070Latency (ms)6050403020100InsertRead1 NodeInsertReadInsert8 NodesRead16 NodesInsertRead32 NodesLower is BetterGridDBCassandraWorkload D Latency (12M Records/Node)120100Latency (ms)806040200InsertRead1 NodeInsertRead8 NodesInsertRead16 NodesInsertRead32 NodesLower is BetterGridDBCassandraPage 17
Workload FWorkload F reads a record, modifies it, and then writes it back. For throughput, higher isbetter and for latency, lower is better.Workload F Throughput (4M records/node)300,000Throughput 0050,00000102030Number of NodesWorkload F Throughput (12M records/node)90,00080,000Throughput ,00020,00010,00000102030Number of NodesPage 18
Workload F Latency (4M Records/Node)300250Latency (ms)2001501005001 Node8 Nodes16 Nodes32 NodesLower is BetterGridDB ReadGridDB Read-Modify-WriteGridDB UpdateCassandra ReadCassandra Read-Modify-WriteCassandra UpdateWorkload F Latency (12M Records/Node)350300Latency (ms)2502001501005001 Node8 Nodes16 Nodes32 NodesLower is BetterGridDB ReadGridDB UpdateCassandra Read-Modify-WriteGridDB Read-Modify-WriteCassandra ReadCassandra UpdatePage 19
Page 20
Long Term Workload AIn update-intensive workloads such as Workload A, Cassandra’s initial results are quitefavorable as its log based architecture allows it to quickly mark a row as deleted and thenappend the new value to the end of the log. Fixstars noticed that over time Cassandra beganto slow down. Fixstars configured an 8-node cluster and loaded 4M and 12M records per nodeand set operationcount to 2 32-1 and let the test run for twenty-four hours.Although it is easier to see the trend with the larger data set, with both tests, Cassandra’sthroughput is less than 50% of what it was in the twenty forth hour versus the first.Meanwhile GridDB’s performance was stable when doing both in and out of memoryoperations.Long Term Workload A Throughput (4M records/node)100000Throughput me (hour)Long Term Workload A Throughput (12M records/node)20000Throughput me (hour)Page 21
Tabular ResultsAll throughput values are “operations per second” and all latency values are “microseconds”.Throughput with Small Data Set (4M Records Per Node)LoadGridDBCassandraWorkload AGridDBCassandraWorkload BGridDBCassandraWorkload CGridDBCassandraWorkload DGridDBCassandraWorkload FGridDBCassandra1 Node8 Nodes16 Nodes32 942Page 22
Latency with Small Data Set (4M Records Per node) -- 1 NodeInsertLoadWorkload AGridDB6.0Cassandra7.0GridDBCassandraWorkload BGridDBCassandraWorkload CGridDBGridDBCassandraWorkload kload DRead 10.76.947.591.644.1Read Read-Mod-WriteUpdateLatency with Small Data Set (4M Records Per node) -- 8 NodesInsertLoadGridDBCassandraWorkload A8.013.3GridDBCassandraWorkload BGridDBCassandraWorkload CGridDBGridDBCassandraWorkload andraWorkload D6.291.04.53.814.244.56.715.79.047.591.644.1Page 23
Latency with Small Data Set (4M Records Per node) -- 16 NodesInsertLoadWorkload AGridDB10.7Cassandra25.7GridDBCassandraWorkload BGridDBCassandraWorkload CGridDBGridDBCassandraWorkload 19.36.3CassandraWorkload 176.0194.518.6Read-Mod-WriteUpdateLatency with Small Data Set (4M Records Per node) -- 32 NodesInsertLoadWorkload AGridDB13.4Cassandra33.6GridDBCassandraWorkload BGridDBCassandraWorkload CGridDBGridDBCassandraWorkload raWorkload DRead164.75.54.977.279.18.721.312.6Page 24
Cassandra213.8237.824.0Throughput with Large Data Set (12M Records Per Node)LoadWorkload AWorkload B1 Node8 Nodes16 Nodes32 83,3997886,2368,96016,212GridDBCassandraWorkload CGridDBCassandraWorkload DWorkload FGridDBCassandraPage 25
Latency with Large Data Set (12M Records Per Node) -- 1 NodeInsertLoadWorkload AGridDB9.7Cassandra7.0GridDBCassandraWorkload BGridDBCassandraWorkload CGridDBGridDBCassandraWorkload 223.824.8CassandraWorkload 6149.1175.226.1Read-Mod-WriteUpdateLatency with Large Data Set (12M Records Per Node) -- 8 NodesInsertLoadWorkload AGridDB12.9Cassandra15.9GridDBCassandraWorkload BGridDBCassandraWorkload CGridDBWorkload rkload 179.333.2Cassandra47.591.644.1Page 26
Latency with Large Data Set (12M Records Per Node) -- 16 NodesInsertLoadWorkload AGridDB14.2Cassandra28.2GridDBCassandraWorkload BGridDBCassandraWorkload CGridDBWorkload 518.418.1CassandraWorkload teLatency with Large Data Set (12M Records Per Node) -- 32 NodesInsertLoadWorkload AGridDB14.5Cassandra40.1GridDBCassandraWorkload BGridDBCassandraWorkload CGridDBWorkload rkload sandra34.762.327.6238.3262.624.3Page 27
ConclusionGridDB’s hybrid storage architecture, in-memory-oriented architecture, outperformsCassandra both in-memory and in operations required using out-of-memory storage. GridDBaccomplishes this while maintaining the same reliability and consistency through twenty-fourhours of operation.The internode communication of GridDB scales significantly better than Cassandra’sdecentralized peer-to-peer system, at least up through 32 nodes. GridDB’s performanceincreases by nearly the same factor as the number of nodes added; Cassandra is only able toscale at 50% of that same factor with this particular Azure instance type.Page 28
AppendicesConfiguration Filesgs e":{"default":"LEVEL ERROR","dataStore":"LEVEL ERROR","collection":"LEVEL ERROR","timeSeries":"LEVEL ERROR","chunkManager":"LEVEL ERROR","objectManager":"LEVEL ERROR","checkpointFile":"LEVEL ERROR","checkpointService":"LEVEL INFO","logManager":"LEVEL WARNING","clusterService":"LEVEL ERROR","syncService":"LEVEL ERROR","systemService":"LEVEL INFO","transactionManager":"LEVEL ERROR","transactionService":"LEVEL ERROR","transactionTimeout":"LEVEL WARNING","triggerService":"LEVEL ERROR","sessionTimeout":"LEVEL WARNING","replicationTimeout":"LEVEL WARNING","recoveryManager":"LEVEL INFO","eventEngine":"LEVEL WARNING","clusterOperation":"LEVEL INFO","ioMonitor":"LEVEL WARNING"Page 29
}}gs ionMember": [{"cluster": {"address":"10.0.0.13", "port":10010},"sync": {"address":"10.0.0.13", "port":10020},"system": {"address":"10.0.0.13", "port":10040},"transaction": {"address":"10.0.0.13", }cassandra.yamlcluster name: 'Test Cluster'num tokens: 256hinted handoff enabled: truehinted handoff throttle in kb: 1024max hints delivery threads: 2hints directory: /var/lib/cassandra/hintshints flush period in ms: 10000max hints file size in mb: 128batchlog replay throttle in kb: 1024authenticator: AllowAllAuthenticatorauthorizer: AllowAllAuthorizerrole manager: CassandraRoleManagerroles validity in ms: 2000permissions validity in ms: 2000credentials validity in ms: 2000partitioner: org.apache.cassandra.dht.Murmur3Partitionerdata file directories:- /var/lib/cassandra/datacommitlog directory: /var/lib/cassandra/commitlogdisk failure policy: stopcommit failure policy: stopkey cache size in mb:key cache save period: 14400row cache size in mb: 0row cache save period: 0counter cache size in mb:Page 30
counter cache save period: 7200saved caches directory: /var/lib/cassandra/saved cachescommitlog sync: periodiccommitlog sync period in ms: 10000commitlog segment size in mb: 32seed provider:- class name: ameters:- seeds: {SEEDS}concurrent reads: 32concurrent writes: 32concurrent counter writes: 32concurrent materialized view writes: 32memtable allocation type: heap buffersindex summary capacity in mb:index summary resize interval in minutes: 60trickle fsync: falsetrickle fsync interval in kb: 10240storage port: 7000ssl storage port: 7001start native transport: truenative transport port: 9042start rpc: falserpc port: 9160rpc keepalive: truerpc server type: syncthrift framed transport size in mb: 15incremental backups: falsesnapshot before compaction: falseauto snapshot: truetombstone warn threshold: 1000tombstone failure threshold: 100000column index size in kb: 64batch size warn threshold in kb: 5batch size fail threshold in kb: 50compaction throughput mb per sec: 16compaction large partition warning threshold mb: 100sstable preemptive open interval in mb: 50read request timeout in ms: 50000range request timeout in ms: 100000write request timeout in ms: 100000counter write request timeout in ms: 100000cas contention timeout in ms: 10000truncate request timeout in ms: 600000request timeout in ms: 900000cross node timeout: falseendpoint snitch: SimpleSnitchdynamic snitch update interval in ms: 100dynamic snitch reset interval in ms: 600000dynamic snitch badness threshold: 0.1Page 31
request scheduler: org.apache.cassandra.scheduler.NoSchedulerserver encryption options:internode encryption: nonekeystore: conf/.keystorekeystore password: cassandratruststore: conf/.truststoretruststore password: cassandraclient encryption options:enabled: falseoptional: falsekeystore: conf/.keystorekeystore password: cassandrainternode compression: allinter dc tcp nodelay: falsetracetype query ttl: 86400tracetype repair ttl: 604800gc warn threshold in ms: 1000enable user defined functions: falseenable scripted user defined functions: falsewindows timer interval: 1transparent data encryption options:enabled: falsechunk length kb: 64cipher: AES/CBC/PKCS5Paddingkey alias: testing:1key provider:- class name: ters:- keystore: conf/.keystorekeystore password: cassandrastore type: JCEKSkey password: cassandraCassandra Schemacreate keyspace ycsb WITH REPLICATION {'class' : 'SimpleStrategy', 'replication factor': 1 };"create table ycsb.usertable ( y id varchar primary key, field0 varchar, field1 varchar, field2 varchar,field3 varchar, field4 varchar, field5 varchar, field6 varchar, field7 varchar, field8 varchar, field9varchar, field10 varchar );"Page 32
Cassandra is a free and open source distributed NoSQL database. Cassandra is considered to have some of the best performance of the major NoSQL databases while maintaining high availability and a decentralized design. The Yahoo! Cloud Serving Benchmark, or YCSB, is a modular benchmark for NoSQL or Key-