Transcription
Taming Operationsin the ApacheHadoop EcosystemJon Hsieh, jon@cloudera.comKate Ting, kate@cloudera.comUSENIX LISA ’14Nov 14, 2014
whoami Jon Hsieh, Cloudera– Software engineer– HBase Tech Lead– Apache HBase committer/PMC Kate Ting, Cloudera– Technical account manager– Apache Sqoop Cookbook coauthor– Former customer operationsengineer 2014 Cloudera, Inc. All rights reserved.2
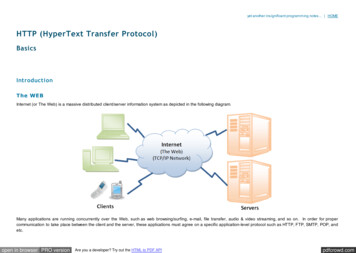
Cloudera and Apache Hadoop Apache Hadoop is an open source software framework for distributed storageand distributed processing of Big Data on clusters of commodity hardware. Cloudera is revolutionizing enterprise data management by offering the firstunified Platform for Big Data, an enterprise data hub built on Apache Hadoop.– Distributes CDH, a distribution Hadoop Distribution.– Teaches, consults, and supports customers building applications on the Hadoop stack.– The world-wide Cloudera Customer Operations Engineering team has closed tens ofthousands of support incidents over six years. 2014 Cloudera, Inc. All rights reserved.3
Outline Anatomy of a Hadoop System Managing Hadoop Clusters Troubleshooting Hadoop Applications 2014 Cloudera, Inc. All rights reserved.4
Anatomy of a HadoopSystem5
2014 Cloudera, Inc. All rights reserved.6
Distributed systems A Distributed system is a set of many processes trying to acting like one a singleprocess. Ideally you only deal with the system as a whole But in practice you deal with the parts And assemble a set of tools to bring it together 2014 Cloudera, Inc. All rights reserved.7
A Hadoop MachineMachineHadoop DaemonsJVMLinuxDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.8
A Hadoop RackRackTop of Rack SwitchMachineMachineMachineHadoop DaemonsHadoop DaemonsHadoop DaemonsJVMJVMJVMLinuxLinuxLinuxDisk, CPU, MemDisk, CPU, MemDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.9
A Hadoop ClusterClusterBackbone SwitchRackRackRackTop of Rack SwitchTop of Rack SwitchMachineMachineMachineTop of Rack SwitchMachine Hadoop DaemonsMachine Hadoop DaemonsMachine Hadoop DaemonsHadoop DaemonsHadoop DaemonsMachineMachine Hadoop DaemonsJVMJVMJVMHadoop DaemonsJVM Linux Hadoop DaemonsJVM Linux Hadoop DaemonsJVM LinuxMachineJVMJVM LinuxLinuxJVM LinuxDisk, CPU, MemDisk, CPU, MemDisk, CPU, MemLinuxLinuxLinuxDisk, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.10
ClusterBackbone SwitchClusterRackWANBackbone SwitchTop of Rack SwitchRackRackTop of Rack SwitchTopof Rack MachineSwitchMachineMachineTop of Rack SwitchTopDaemonsof Rack Switch Hadoop DaemonsHadoopHadoop ineTopof Rack MachineSwitch Hadoop DaemonsMachine Hadoop DaemonsDaemonsMachine HadoopHadoop DaemonsHadoop DaemonsJVMJVMJVMMachine Hadoop DaemonsMachineMachineHadoop DaemonsHadoop DaemonsHadoop DaemonsHadoop hineMachineLinuxMachine LinuxJVMJVMJVMJVM LinuxHadoop DaemonsJVM LinuxHadoop DaemonsJVM LinuxHadoop DaemonsJVM LinuxDisk, CPU, MemJVM Linux Disk, CPU, MemJVM Linux Disk, CPU, MemLinuxLinuxLinuxJVM LinuxDisk, CPU, Mem JVM LinuxDisk, CPU, Mem JVM LinuxDisk, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, MemLinuxLinuxLinuxDisk, CPU, MemDisk, CPU, MemDisk, CPU, MemRackRackDisk, CPU, MemDisk, CPU, MemDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.11
Hadoop StackMachineMachineMachineMachineHadoop DaemonsHadoop DaemonsHadoop DaemonsHadoop DaemonsJVMJVMJVMJVMLinuxLinuxLinuxLinuxDisk, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.12
Hadoop Stack - StorageMachineHadoop DaemonsRandom Access Storage: HBaseMachineMachineFile Storage:HDFSHadoopDaemonsHadoop k, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.13
Hadoop Stack - ProcessingBatch processingMapReduceIn Mem processing:SparkInteractive SQL:ImpalaSearch: SolrResource Management: YARNMachineHadoop DaemonsRandom Access Storage: HBaseMachineMachineFile Storage:HDFSHadoopDaemonsHadoop k, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.14
In Mem processing:SparkSearch: SolrResource Management: YARNMachineHadoop DaemonsRandom Access Storage: HBaseMachineMachineFile Storage:HDFSHadoopDaemonsHadoop k, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.DB Import Export:SqoopBatch processingMapReduceInteractive SQL:ImpalaEvent ingest: Flume,KafkaHadoop Stack - IntegrationOther systems:httpd, sas,custom appsetc15
Hadoop Stack – User InterfaceBatch processingMapReduceIn Mem processing:SparkInteractive SQL:ImpalaSearch: SolrResource Management: YARNMachineHadoop DaemonsRandom Access Storage: HBaseMachineMachineFile Storage:HDFSHadoopDaemonsHadoop k, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.DB Import Export:SqoopLanguages/APIs: Hive, Pig, Crunch, Kite, MahoutEvent ingest: Flume,KafkaUser interface: HUEOther systems:httpd, sas,custom appsetc16
Hadoop StackBatch processingMapReduceIn Mem processing:SparkInteractive SQL:ImpalaSearch: SolrResource Management: YARNMachineHadoop DaemonsRandom Access Storage: HBaseMachineMachineFile Storage:HDFSHadoopDaemonsHadoop k, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.DB Import Export:SqoopLanguages/APIs: Hive, Pig, Crunch, Kite, MahoutEvent ingest: Flume,KafkaUser interface: HUEOther systems:httpd, sas,custom appsetc17
Managing a Hadoop Cluster18
Understanding Normal Establish normal– Boring logs are good So that you can detect abnormal– Find anomalies and outliers– Compare performance And then isolate root causes– Who are the suspects– Pull the thread by interrogating– Correlate across different subsystems 2014 Cloudera, Inc. All rights reserved.19
Basic tools What happened?– Logs What state are we in now?– Metrics– Thread stacks What happens when I do this?– Tracing– Dumps Is it alive?– listings– Canaries Is it OK?– fsck 2014 Cloudera, Inc. All rights reserved.20
Diagnostics for single machinesMachineLinuxDisk, CPU, MemAnalysis and Tools via @brendangregg 2014 Cloudera, Inc. All rights reserved.21
Diagnosis ToolsHW/KernelJVMHadoop StackLogs/log, /var/logdmesgEnable gc logging*:/var/log/hadoo hbase Metrics/proc, top, iotop, sar,vmstat, netstatjstat*:/stacks, *:/jmx,TracingStrace, tcpdumpDebugger, jdb, jstackhtraceDumpsCore dumpsjmapEnable OOME dump*:/dumpLivenesspingJpsWeb UICorruptfsckHdfs fsck, hbase hbck 2014 Cloudera, Inc. All rights reserved.22
Diagnostics for the JVM Most Hadoop services run in the Java VM, intros new java subsystems– Just in time compiler– Threads– Garbage collection Dumping Current threads– jstacks (any threads stuck or blocked?) JVM Settings:– Enabling GC Logs: -XX: PrintGCDateStamps -XX: PrintGCDetails– Enabling OOME Heap dumps: -XX: HeapDumpOnOutOfMemoryErrorMachineHadoop DaemonsJVMLinux Metrics on GC– Get gc counts and info with jstat Memory Usage dumps– Create heap dump: jmap –dump:live,format b,file heap.bin pid – View heap dump from crash or jmap with jhatDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.23
Diagnosis ToolsHW/KernelJVMHadoop StackLogs/log, /var/logdmesgEnable gc logging*:/var/log/hadoo hbase Metrics/proc, top, iotop, sar,vmstat, netstatjstat*:/stacks, *:/jmx,TracingStrace, tcpdumpDebugger, jdb, jstackhtraceDumpsCore dumpsjmapEnable OOME dump*:/dumpLivenesspingJpsWeb UICorruptfsckHdfs fsck, hbase hbck 2014 Cloudera, Inc. All rights reserved.24
Tools for lots of machinesMachineMachineMachineMachineHadoop DaemonsHadoop DaemonsHadoop DaemonsHadoop DaemonsJVMJVMJVMJVMLinuxLinuxLinuxLinuxDisk, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.Other systems:httpd, sas,custom appsetc25
Tools for lots of machinesMachineMachineHadoop DaemonsMachineHadoop DaemonsMachineHadoop DaemonsHadoop DaemonsJVMJVM Ganglia*, Nagios*JVMJVMLinuxLinuxLinuxLinuxDisk, CPU, MemGanglia, NagiosDisk, CPU, MemDisk, CPU, MemOther systems:httpd, sas,custom appsetcDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.26
Ganglia Collects and aggregates metrics from machines Good for what’s going on right now and describing normal perf Organized by physical resource (CPU, Mem, Disk)– Good defaults– Good for pin pointing machines– Good for seeing overall utilization– Uses RRDTool under the covers Some data scalability limitations, lossy over time. Dynamic for new machines, requires config for new metrics 2014 Cloudera, Inc. All rights reserved.27
Graphite Popular alternative to ganglia Can handle the scale of metrics coming in Similar to ganglia, but uses its own RRDdatabase. More aimed at dynamic metrics (asopposed to statically defined metrics) 2014 Cloudera, Inc. All rights reserved.28
Nagios Provides alerts from canaries and basic health checks for services onmachines Organized by Service (httpd, dns, etc) Defacto standard for service monitoring Lacks distributed system know how– Requires bespoke setup for service slaves and masters– Lacks details with multitenant services or short-lived jobs 2014 Cloudera, Inc. All rights reserved.29
Tools for the Hadoop StackMachineMachineHadoop DaemonsMachineHadoop DaemonsMachineHadoop DaemonsHadoop DaemonsJVMJVM Ganglia*, Nagios*JVMJVMLinuxLinuxLinuxLinuxDisk, CPU, MemGanglia, NagiosDisk, CPU, MemDisk, CPU, MemOther systems:httpd, sas,custom appsetcDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.30
Tools for the Hadoop StackBatch processingMapReduceIn Mem processing:SparkInteractive SQL:ImpalaSearch: SolrResource Management: YARNMachineHadoop DaemonsRandom Access Storage: HBaseMachineMachineFile Storage:HDFSHadoopDaemonsHadoop onsSentryHadoopJVMJVM Ganglia*, Nagios*JVMJVMLinuxLinuxLinuxLinuxDisk, CPU, MemGanglia, NagiosDisk, CPU, MemDisk, CPU, MemDB Import Export:SqoopLanguages/APIs: Hive, Pig, Crunch, Kite, MahoutEvent ingest: Flume,KafkaUser interface: HUEOther systems:httpd, sas,custom appsetcDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.31
Tools for the Hadoop StackBatch processingMapReduceIn Mem processing:SparkInteractive SQL:ImpalaSearch: SolrResource Management: YARNMachineHadoop DaemonsRandom Access Storage: HBaseMachineMachineFile Storage:HDFSHadoopDaemonsHadoop onsSentryHadoopJVMJVM Ganglia*, Nagios*JVMJVMLinuxLinuxLinuxLinuxDisk, CPU, MemGanglia, NagiosDisk, CPU, MemDisk, CPU, MemDB Import Export:SqoopLanguages/APIs: Hive, Pig, Crunch, Kite, MahoutEvent ingest: Flume,KafkaUser interface: HUEOther systems:httpd, sas,custom appsetcDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.32
Diagnostics for the Hadoop Stack Single client call can trigger many RPCs spanning many machines Systems are evolving quickly A failure on one daemon, by design, does not cause failure of the entire service Logs:– Each service’s master and slaves have their own logs: /var/log/– There are lot of logs and they change frequently Metrics:– Each daemon offers metrics, often aggregated at masters Tracing:– Htrace (integrated into Hadoop, HBase, recently in Apache Incubator) Liveness:– Canaries, service/daemon web uis 2014 Cloudera, Inc. All rights reserved.33
Diagnosis ToolsHW/KernelJVMHadoop StackLogs/log, /var/logdmesgEnable gc logging*:/var/log/hadoo hbase Metrics/proc, top, iotop, sar,vmstat, netstatjstat*:/stacks, *:/jmx,TracingStrace, tcpdumpDebugger, jdb, jstackhtraceDumpsCore dumpsjmapEnable OOME dump*:/dumpLivenesspingJpsWeb UICorruptfsckHDFS fsck, HBase hbck 2014 Cloudera, Inc. All rights reserved.34
Tools for the Hadoop StackBatch processingMapReduceIn Mem processing:SparkInteractive SQL:ImpalaSearch: SolrResource Management: YARNMachineHadoop DaemonsRandom Access Storage: HBaseMachineMachineFile Storage:HDFSHadoopDaemonsHadoop onsSentryHadoopJVMJVM Ganglia*, Nagios*JVMJVMLinuxLinuxLinuxLinuxDisk, CPU, MemGanglia, NagiosDisk, CPU, MemDisk, CPU, MemDB Import Export:SqoopLanguages/APIs: Hive, Pig, Crunch, Kite, MahoutEvent ingest: Flume,KafkaUser interface: HUEOther systems:httpd, sas,custom appsetcDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.35
Tools for the Hadoop StackBatch processingLogs and MetricsMapReduceIn Mem processing:Logs and MetricsSparkInteractive SQL:Logs and MetricsImpalaSearch:SolrLogsand MetricsResourceLogsManagement:and Metrics YARNRandomAccess Storage: HBaseLogsand MetricsHTraceMachineMachineMachineMetricsFile Storage:HDFSHadoop Daemons Logs chinezookeeper;Logsand MetricsSecurity:DaemonsSentryHadoopJVMJVMjmx, jstack, jstat, GC logs JVMJVMLinuxLinuxLinux/proc, dmesg, /var/logs/Disk, CPU, MemDisk, CPU, MemLinuxDisk, CPU, MemDB Import Export:LogsSqoopLanguages/APIs: Hive,LogsPig, Crunch, Kite, MahoutEvent ingest: Flume,Logs and MetricsKafkaUserHUELogsinterface:and MetricsOther systems:Customapphttpd, sas,logsappscustometcDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.36
Tools for the Hadoop StackBatch processingMapReduceIn Mem processing:SparkInteractive SQL:ImpalaSearch: SolrResource Management: YARNGanglia*, Nagios* ?MachineHadoop DaemonsRandom Access Storage: HBaseMachineMachineFile Storage:HDFSHadoopDaemonsHadoop onsSentryHadoopJVMJVM Ganglia*, Nagios*JVMJVMLinuxLinuxLinuxLinuxDisk, CPU, MemGanglia, NagiosDisk, CPU, MemDisk, CPU, MemDB Import Export:SqoopLanguages/APIs: Hive, Pig, Crunch, Kite, MahoutEvent ingest: Flume,KafkaUser interface: HUEOther systems:httpd, sas,custom appsetcDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.37
Ganglia and Nagios are not enough Fault tolerant distributed system masks many problems (by design!)– Some failures are not critical – failure condition more complicated Lacks distributed system know how– Requires bespoke setup for service slaves and masters– Lacks details with multitenant services or short-lived jobs Hadoop services are logically dependent on each other– Need to correlate metrics across different service and machines– Need to correlate logs from different services and machines.– Young systems where Logs are changing frequently– What about all the logs?– What of all these metrics do we really need? Some data scalability limitations, lossy over time– What about full fidelity? 2014 Cloudera, Inc. All rights reserved.38
OpenTSDB OpenTSDB (Time Series Database)– Efficiently stores metric data into HBase– Keeps data at full fidelity– Keep as much data as your HBase instance canhandle. Free and Open Source 2014 Cloudera, Inc. All rights reserved.39
Cloudera Manager Extracts hardware, OS, and Hadoop service metricsspecifically relevant to Hadoop and its related services.––––– Operation Latencies# of disk seeksHDFS data writtenJava GC timeNetwork IOProvides– Cluster preflight checks– Basic host checks– Regular health checks Uses RRD Provides distributed log search Monitors logs for known issues Point and click for useful utils (lsof, jstack, jmap) Free 2014 Cloudera, Inc. All rights reserved.40
Tools for the Hadoop StackBatch processingMapReduceIn Mem processing:SparkInteractive SQL:ImpalaSearch: SolrFull Fidelitymetrics:YARNResourceManagement:Open TSDB*Metrics Logs:Logs:Cloudera ManagerSearch a la SplunkCoordination:Random Access Storage: y:DaemonsSentryFile Storage:HDFSHadoop DaemonsHadoopDaemonsHadoopHadoop DaemonsJVMJVM Ganglia*, Nagios*JVMJVMLinuxLinuxLinuxLinuxDisk, CPU, MemGanglia, NagiosDisk, CPU, MemDisk, CPU, MemDB Import Export:SqoopLanguages/APIs: Hive, Pig, Crunch, Kite, MahoutEvent ingest: Flume,KafkaUser interface: HUEOther systems:httpd, sas,custom appsetcDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.41
Troubleshooting a HadoopSystem42
The Law of Cluster InertiaA cluster in a good state stays in a good state,anda cluster in a bad state stays in a bad state,unlessacted upon by an external force. 2014 Cloudera, Inc. All rights reserved.43
2014 Cloudera, Inc. All rights reserved.44
External Forces Failures Acts of God Users Admins 2014 Cloudera, Inc. All rights reserved.45
Failures as an External ForceBatch processingJobMapReduceIn Mem processing:SparkInteractive SQL:ImpalaSearch: SolrResource Management: YARNMachineHadoop DaemonsJVMMachineLinuxDisk, CPU, MemRandom Access Storage: HBaseSlaveMachineMachineFile Storage:HDFSHadoopDaemonsHadoop onsSentryHadoopJVMJVMJVMJVMLinuxLinuxLinuxDisk, CPU, MemDisk, HWCPU, MemDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.DB Import Export:SqoopLanguages/APIs: Hive, Pig, Crunch, Kite, MahoutEvent ingest: Flume,KafkaUser interface: HUEOther systems:httpd, sas,custom appsetc46
Acts of God as an External ForceWANClusterBackbone SwitchRackTop of Rack SwitchRackRackTop of Rack SwitchMachineMachineMachineTop of Rack SwitchMachine Hadoop DaemonsMachine Hadoop DaemonsMachine Hadoop DaemonsPowerHadoop DaemonsHadoop DaemonsMachineMachineMachine Hadoop DaemonsJVMJVMJVMFailureHadoop DaemonsHadoop DaemonsHadoop DaemonsJVMLinuxJVMLinuxJVMLinuxJVMJVM LinuxLinuxJVM LinuxDisk, CPU, MemDisk, CPU, MemDisk, CPU, MemLinuxLinuxLinuxDisk, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.47
Users as an external force Use Security to protect systems from users– Prevent and track Authentication – proving who you are– LDAP, Kerberos Authorization – deciding what you are allowed to do– Apache Sentry (incubating), Hadoop security, HBase security Audit – who and when was something done?– Cloudera Navigator 2014 Cloudera, Inc. All rights reserved.48
Admins as an external forceUpgradesMisconfiguration Linux Memory Mismanagement– TT OOME– JT OOME– Native Threads Hadoop Java Thread Mismanagement– Fetch Failures– Replicas Disk Mismanagement– No File– Too Many Files 2014 Cloudera, Inc. All rights reserved.49
Debugging HadoopApplications50
Example Application ingestprocessexport 2014 Cloudera, Inc. All rights reserved.51
Custom app feeds eventdata in to HBaseMachineHadoop DaemonsRandom Access Storage: HBaseMachineMachineFile Storage:HDFSHadoopDaemonsHadoop k, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.Event ingest: Flume,KafkaExample Application Pipeline - IngestOther systems:httpd, sas,custom appsetc52
Languages/APIs: Hive, Pig, Crunch, Kite, MahoutBatch processingMapReduceMap Reduce Job generatesnew artifact from HBase dataand writes to hdfsResource Management: YARNMachineHadoop DaemonsRandom Access Storage: HBaseMachineMachineFile Storage:HDFSHadoopDaemonsHadoop k, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.Event ingest: Flume,KafkaExample Application Pipeline - processingOther systems:httpd, sas,custom appsetc53
Languages/APIs: Hive, Pig, Crunch, Kite, MahoutEvent ingest: Flume,KafkaSqoop result intorelational databaseto serve applicationBatch processingMapReduceResource Management: YARNMachineHadoop DaemonsRandom Access Storage: HBase9MachineMachineFile Storage:HDFSHadoopDaemonsHadoop k, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.DB Import Export:SqoopExample Application Pipeline - exportOther systems:httpd, sas,custom appsetc54
Case study 1: slow jobs after Hadoop upgradeSymptom:After an upgrade,activity on the clustereventually began toslow down and the jobqueue overflowed. 2014 Cloudera, Inc. All rights reserved.55
Finding the right part of the stackE-SPORE (from Eric Sammer’s Hadoop Operations) Environment– What is different about the environment now from the last time everything worked? Stack– The entire cluster also has shared dependency on data center infrastructure such as the network, DNS, and other services. Patterns– Are the tasks from the same job? Are they all assigned to the same tasktracker? Do they all use a shared library that was changedrecently? Output– Always check log output for exceptions but don’t assume the symptom correlates to the root cause. Resources– Do local disks have enough? Is the machine swapping? Does the network utilization look normal? Does the CPU utilization looknormal? Event correlation– It’s important to know the order in which the events led to the failure. 2014 Cloudera, Inc. All rights reserved.56
Languages/APIs: Hive, Pig, Crunch, Kite, MahoutBatch processingMapReduceMap Reduce Job generatesnew artifact from HBase dataand writes to hdfsResource Management: YARNMachineHadoop DaemonsRandom Access Storage: HBaseMachineMachineFile Storage:HDFSHadoopDaemonsHadoop k, CPU, MemDisk, CPU, MemDisk, CPU, MemDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.Event ingest: Flume,KafkaExample Application Pipeline - processingOther systems:httpd, sas,custom appsetc57
Case study 1: slow jobs after Hadoop upgradeEvidence:Isolated to Processing phase (MR).In TT Logs, found an innocuous butanomalous log entry about “fetchfailures.”Many users had run in to this MRproblem using different versions of MR.Workaround provided: remove theproblem node from the cluster. 2014 Cloudera, Inc. All rights reserved.58
MachineHadoop DaemonsJVMLinuxDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.
Case study 1: slow jobs after Hadoop upgradeRoot cause:All MR versions had acommon dependency on aparticular version of Jetty(Jetty 6.1.26) .Dev was able to reproduceand fix the bug in Jetty. 2014 Cloudera, Inc. All rights reserved.60
Case study 2: slow jobs after Linux upgradeSymptom:After an upgrade,system CPU usagepeaked at 30% ormore of the totalCPU usage. 2014 Cloudera, Inc. All rights reserved.61
Case study 2: slow jobs after Linux upgradeEvidence:Used tracing tools toisolate a majority of timewas inexplicably spent invirtual memory -transparenthuge-pages-and-hadoop-workloads/ 2014 Cloudera, Inc. All rights reserved.62
MachineHadoop DaemonsJVMLinuxDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.
Case study 2: slow jobs after Linux upgradeRoot cause:Running RHEL or CentOSversions 6.2, 6.3, and 6.4 orSLES 11 SP2 has a featurecalled "Transparent HugePage (THP)" compactionwhich interacts poorly withHadoop workloads. 2014 Cloudera, Inc. All rights reserved.64
Case study 3: slow jobs at a precise momentSymptom:High CPU usage andresponsive but sluggishcluster.30 customers all hit thisat the exact same time:6/30/12 at 5pm PDT. 2014 Cloudera, Inc. All rights reserved.65
Case study 3: slow jobs at a precise momentEvidence:Checked the kernelmessage buffer (rundmesg) and look for outputconfirming the leap secondinjection.Other systems had sameproblem. 2014 Cloudera, Inc. All rights reserved.66
MachineHadoop DaemonsJVMLinuxDisk, CPU, Mem 2014 Cloudera, Inc. All rights reserved.
Case study 3: slow jobs at a precise momentRoot cause:Linux OS kernelmishandled a leapsecond added. 2014 Cloudera, Inc. All rights reserved.68
Similar symptoms, different problem 2014 Cloudera, Inc. All rights reserved.69
Case study 1: slow jobs after Hadoop upgradeSymptomEvidenceRoot CauseAfter an upgrade, activity on thecluster eventually began to slowdown and the job queueoverflowed.In TT Logs, found an innocuous butanomalous log entry about “fetch failures.”Many users had run in to this MR problemusing different versions of MR.All MR versions had a commondependency on a particularversion of Jetty (Jetty 6.1.26) .Workaround provided: remove the problemnode from the cluster.Dev was able to reproduce and fixthe bug in Jetty. 2014 Cloudera, Inc. All rights reserved.70
Case study 2: slow jobs after Linux upgradeSymptomEvidenceRoot CauseAfter an upgrade, system CPUusage peaked at 30% or more ofthe total CPU usage.HT to Greg Rahn ,Brendan Gregg’sflame graph tool, and perf toolwhich proved that majority of timewas inexplicably spent in virtualmemory calls.Running RHEL or CentOS versions 6.2, 6.3,and 6.4 or SLES 11 SP2 has a feature called"Transparent Huge Page (THP)"compaction which interacts poorly withHadoop workloads. 2014 Cloudera, Inc. All rights reserved.71
Case study 3: slow jobs at a precise momentSymptomEvidenceRoot CauseHigh CPU usage and responsivebut sluggish cluster.Checked the kernel messagebuffer (run dmesg) and look foroutput confirming the leap secondinjection.Linux OS kernel mishandled a leap secondadded on 6/30/12 at 5pm PDT.30 customers all hit this at theexact same time. 2014 Cloudera, Inc. All rights reserved.72
Lessons learnedMethodologyToolsLearn from failureMore crucial than thespecific troubleshootingmethodology used is to useone.More crucial than thespecific tool used is the typeof data analyzed and how it’sanalyzed.Capture for posterity in aknowledge base article, blogpost, or conferencepresentation. 2014 Cloudera, Inc. All rights reserved.73
Conclusions74
TakeawayAnatomy of a Hadoop SystemManaging Hadoop ClustersTroubleshooting Hadoop ApplicationsA cluster in a good state stays in agood state, and a cluster in a badstate stays in a bad state, unlessacted upon by an external force.Cloudera has seen a lot of diverseclusters and used that experienceto build tools to help diagnose andunderstand how Hadoop operates.Similar symptoms can lead todifferent root causes. Use tools toassist with event correlation andpattern determination. 2014 Cloudera, Inc. All rights reserved.75
Shameless plugCloudera LiveCloudera CommunityIn Europe!A full demo cluster tutorial and sampledata/queries in the cloud – free access fortwo weeks (plus, clusters in Tableau andZoomdata flavors!)Ask technical questions/gettechnical answers from ClouderaSoftware Engineers and otherusersAccount Executives, SolutionsArchitects, era.com/community 2014 Cloudera, Inc. All rights reserved.76
Thank you!Office hours @2pm inWillow A@jmhsieh@kate ting
3 Cloudera and Apache Hadoop Apache Hadoop is an open source software framework for distributed storage and distributed processing of Big Data on clusters of commodity hardware. Cloudera is revolutionizing enterprise data management by o!ering the first unified Platform for Big Data, an enterprise data hub built on Apache Hadoop.