Transcription
Natural LanguageProcessing withSpark NLPLearning to Understand Text at ScaleAlex Thomas
Natural Language Processingwith Spark NLPLearning to Understand Text at ScaleAlex ThomasBeijingBoston Farnham SebastopolTokyo
Natural Language Processing with Spark NLPby Alex ThomasCopyright 2020 Alex Thomas. All rights reserved.Printed in the United States of America.Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472.O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions arealso available for most titles (http://oreilly.com). For more information, contact our corporate/institutionalsales department: 800-998-9938 or corporate@oreilly.com.Acquisitions Editor: Mike LoukidesDevelopmental Editors: Nicole Taché, Gary O’BrienProduction Editor: Beth KellyCopyeditor: Piper EditorialProofreader: Athena LakriJuly 2020:Indexer: WordCo, Inc.Interior Designer: David FutatoCover Designer: Karen MontgomeryIllustrator: Rebecca DemarestFirst EditionRevision History for the First Edition2020-06-24:First ReleaseSee http://oreilly.com/catalog/errata.csp?isbn 9781492047766 for release details.The O’Reilly logo is a registered trademark of O’Reilly Media, Inc. Natural Language Processing with SparkNLP, the cover image, and related trade dress are trademarks of O’Reilly Media, Inc.The views expressed in this work are those of the author, and do not represent the publisher’s views.While the publisher and the author have used good faith efforts to ensure that the information andinstructions contained in this work are accurate, the publisher and the author disclaim all responsibilityfor errors or omissions, including without limitation responsibility for damages resulting from the use ofor reliance on this work. Use of the information and instructions contained in this work is at your ownrisk. If any code samples or other technology this work contains or describes is subject to open sourcelicenses or the intellectual property rights of others, it is your responsibility to ensure that your usethereof complies with such licenses and/or rights.978-1-492-04776-6[LSI]
Table of ContentsPreface. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xiPart I.Basics1. Getting Started. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3IntroductionOther ToolsSetting Up Your EnvironmentPrerequisitesStarting Apache SparkChecking Out the CodeGetting Familiar with Apache SparkStarting Apache Spark with Spark NLPLoading and Viewing Data in Apache SparkHello World with Spark NLP356667788112. Natural Language Basics. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19What Is Natural Language?Origins of LanguageSpoken Language Versus Written LanguageLinguisticsPhonetics and : Dialects, Registers, and Other VarietiesFormality19202122222324252526iii
ContextPragmaticsRoman JakobsonHow To Use PragmaticsWriting gographsEncodingsASCIIUnicodeUTF-8Exercises: TokenizingTokenize EnglishTokenize GreekTokenize Ge’ez 353536363. NLP on Apache Spark. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39Parallelism, Concurrency, Distributing ComputationParallelization Before Apache HadoopMapReduce and Apache HadoopApache SparkArchitecture of Apache SparkPhysical ArchitectureLogical ArchitectureSpark SQL and Spark MLlibTransformersEstimators and ModelsEvaluatorsNLP LibrariesFunctionality LibrariesAnnotation LibrariesNLP in Other LibrariesSpark NLPAnnotation LibraryStagesPretrained PipelinesFinisheriv Table of Contents4043434444444651545760636363646565657274
Exercises: Build a Topic ModelResources76774. Deep Learning Basics. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79Gradient DescentBackpropagationConvolutional Neural NetworksFiltersPoolingRecurrent Neural NetworksBackpropagation Through TimeElman NetsLSTMsExercise 1Exercise 2Resources8485969697979798989999100Part II. Building Blocks5. Processing Words. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103TokenizationVocabulary ReductionStemmingLemmatizationStemming Versus LemmatizationSpelling N-GramVisualizing: Word and Document 121131141161181221226. Information Retrieval. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123Inverted IndicesBuilding an Inverted IndexVector Space ModelStop-Word RemovalInverse Document FrequencyIn Spark124124130133134137Table of Contents v
ExercisesResources1371387. Classification and Regression. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139Bag-of-Words FeaturesRegular Expression FeaturesFeature SelectionModelingNaïve BayesLinear ModelsDecision/Regression TreesDeep Learning 501501538. Sequence Modeling with Keras. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155Sentence Segmentation(Hidden) Markov ModelsSection SegmentationPart-of-Speech TaggingConditional Random FieldChunking and Syntactic ParsingLanguage ModelsRecurrent Neural NetworksExercise: Character N-GramsExercise: Word Language ModelResources1561561631641681681691701761761779. Information Extraction. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179Named-Entity RecognitionCoreference ResolutionAssertion Status DetectionRelationship ExtractionSummaryExercises17918718919119519610. Topic Modeling. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197K-MeansLatent Semantic IndexingNonnegative Matrix FactorizationLatent Dirichlet AllocationExercisesvi Table of Contents198202205209211
11. Word Embeddings. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 215Word2vecGloVefastTextTransformersELMo, BERT, and XLNetdoc2vecExercises215226227227228229231Part III. Applications12. Sentiment Analysis and Emotion Detection. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 235Problem Statement and ConstraintsPlan the ProjectDesign the SolutionImplement the SolutionTest and Measure the SolutionBusiness MetricsModel-Centric MetricsInfrastructure MetricsProcess MetricsOffline Versus Online Model MeasurementReviewInitial DeploymentFallback PlansNext 924925025013. Building Knowledge Bases. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 251Problem Statement and ConstraintsPlan the ProjectDesign the SolutionImplement the SolutionTest and Measure the SolutionBusiness MetricsModel-Centric MetricsInfrastructure MetricsProcess 264264Table of Contents vii
14. Search Engine. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 265Problem Statement and ConstraintsPlan the ProjectDesign the SolutionImplement the SolutionTest and Measure the SolutionBusiness MetricsModel-Centric 15. Chatbot. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 277Problem Statement and ConstraintsPlan the ProjectDesign the SolutionImplement the SolutionTest and Measure the SolutionBusiness MetricsModel-Centric 16. Object Character Recognition. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 291Kinds of OCR TasksImages of Printed Text and PDFs to TextImages of Handwritten Text to TextImages of Text in Environment to TextImages of Text to TargetNote on Different Writing SystemsProblem Statement and ConstraintsPlan the ProjectImplement the SolutionTest and Measure the SolutionModel-Centric MetricsReviewConclusionPart IV.291291292292293293294294295299300300300Building NLP Systems17. Supporting Multiple Languages. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303Language Typologyviii Table of Contents303
Scenario: Academic Paper ClassificationText Processing in Different LanguagesCompound WordsMorphological ComplexityTransfer Learning and Multilingual Deep LearningSearch Across 0818. Human Labeling. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 309GuidelinesScenario: Academic Paper ClassificationInter-Labeler AgreementIterative LabelingLabeling 31231331431431431531519. Productionizing NLP Applications. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 317Spark NLP Model CacheSpark NLP and TensorFlow IntegrationSpark Optimization BasicsDesign-Level OptimizationProfiling ToolsMonitoringManaging Data ResourcesTesting NLP-Based ApplicationsUnit TestsIntegration TestsSmoke and Sanity TestsPerformance TestsUsability TestsDemoing NLP-Based ApplicationsChecklistsModel Deployment ChecklistScaling and Performance ChecklistTesting 23324324325325325326326327Table of Contents ix
Glossary. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 329Index. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 339x Table of Contents
PrefaceWhy Natural Language Processing Is Importantand DifficultNatural language processing (NLP) is a field of study concerned with processing lan‐guage data. We will be focusing on text, but natural language audio data is also a partof NLP. Dealing with natural language text data is difficult. The reason it is difficult isthat it relies on three fields of study: linguistics, software engineering, and machinelearning. It is hard to find the expertise in all three for most NLP-based projects. For‐tunately, you don’t need to be a world-class expert in all three fields to make informeddecisions about your application. As long as you know some basics, you can use libra‐ries built by experts to accomplish your goals. Consider the advances made in creat‐ing efficient algorithms for vector and matrix operations. If the common linearalgebra libraries that deep learning libraries use were not available, imagine howmuch harder it would have been for the deep learning revolution to begin. Eventhough these libraries mean that we don’t need to implement cache aware matrixmultiplication for every new project, we still need to understand the basics of linearalgebra and the basics of how the operations are implemented to make the best use ofthese libraries. I believe the situation is becoming the same for NLP and NLPlibraries.Applications that use natural language (text, spoken, and gestural) will always be dif‐ferent than other applications due to the data they use. The benefit and draw to theseapplications is how much data is out there. Humans are producing and churning nat‐ural language data all the time. The difficult aspects are that people are literallyevolved to detect mistakes in natural language use, and the data (text, images, audio,and video) is not made with computers in mind. These difficulties can be overcomethrough a combination of linguistics, software engineering, and machine learning.xi
This book deals with text data. This is the easiest of the data types that natural lan‐guage comes in, because our computers were designed with text in mind. That beingsaid, we still want to consider a lot of small and large details that are not obvious.BackgroundA few years ago, I was working on a tutorial for O’Reilly. This tutorial was aboutbuilding NLP pipelines on Apache Spark. At the time, Apache Spark 2.0 was still rela‐tively new, but I was mainly using version 1.6. I thought it would be cool to build anannotation library using the new DataFrames and pipelines; alas, I was not able toimplement this for the tutorial. However, I talked about this with my friend (andtutorial copresenter) David Talby, and we created a design doc. I didn’t have enoughtime to work on building the library, so I consulted Saif Addin, whom David hadhired to work on the project. As the project grew and developed, David, ClaudiuBranzan (another friend and colleague), and I began presenting tutorials at conferen‐ces and meetups. It seemed like there was an interest in learning more about thelibrary and an interest in learning more about NLP in general.People who know me know I am rant-prone, and few topics are as likely to get mestarted as NLP and how it is used and misused in the technology industry. I think thisis because of my background. Growing up, I studied linguistics as a hobby—an allconsuming hobby. When I went to university, even though I focused on mathematics,I also took linguistics courses. Shortly before graduating, I decided that I also wantedto learn computer science, so I could take the theoretical concepts I had learned andcreate something. Once I began in the industry, I learned that I could combine thesethree interests into one: NLP. This gives me a rare view of NLP because I studied itscomponents first individually and then combined.I am really excited to be working on this book, and I hope this book helps you inbuilding your next NLP application!PhilosophyAn important part of the library is the idea that people should build their own mod‐els. There is no one-size-fits-all method in NLP. If you want to build a successful NLPapplication, you need to understand your data as well as your product. Prebuilt mod‐els are useful for initial versions, demos, and tutorials. This means that if you want touse Spark NLP successfully, you will need to understand how NLP works. So in thisbook we will cover more than just Spark NLP API. We will talk about how to useSpark NLP, but we will also talk about how NLP and deep learning work. When youcombine an understanding of NLP with a library that is built with the intent of cus‐tomization, you will be able to build NLP applications that achieve your goals.xii Preface
Conventions Used in This BookThe following typographical conventions are used in this book:ItalicIndicates new terms, URLs, email addresses, filenames, and file extensions.Constant widthUsed for program listings, as well as within paragraphs to refer to program ele‐ments such as variable or function names, databases, data types, environmentvariables, statements, and keywords.Constant width boldShows commands or other text that should be typed literally by the user.Constant width italicShows text that should be replaced with user-supplied values or by values deter‐mined by context.This element signifies a general note.Using Code ExamplesSupplemental material (code examples, exercises, etc.) is available for download athttps://oreil.ly/SparkNLP.If you have a technical question or a problem using the code examples, please send anemail to bookquestions@oreilly.com.This book is here to help you get your job done. In general, if example code is offeredwith this book, you may use it in your programs and documentation. You do notneed to contact us for permission unless you’re reproducing a significant portion ofthe code. For example, writing a program that uses several chunks of code from thisbook does not require permission. Selling or distributing examples from O’Reillybooks does require permission. Answering a question by citing this book and quotingexample code does not require permission. Incorporating a significant amount ofexample code from this book into your product’s documentation does requirepermission.We appreciate, but generally do not require, attribution. An attribution usuallyincludes the title, author, publisher, and ISBN. For example: Natural LanguagePreface xiii
Processing with Spark NLP by Alex Thomas (O’Reilly). Copyright 2020 Alex Thomas,978-1-492-04776-6.”If you feel your use of code examples falls outside fair use or the permission givenabove, feel free to contact us at permissions@oreilly.com.O’Reilly Online LearningFor more than 40 years, O’Reilly Media has provided technol‐ogy and business training, knowledge, and insight to helpcompanies succeed.Our unique network of experts and innovators share their knowledge and expertisethrough books, articles, and our online learning platform. O’Reilly’s online learningplatform gives you on-demand access to live training courses, in-depth learningpaths, interactive coding environments, and a vast collection of text and video fromO’Reilly and 200 other publishers. For more information, visit http://oreilly.com.How to Contact UsPlease address comments and questions concerning this book to the publisher:O’Reilly Media, Inc.1005 Gravenstein Highway NorthSebastopol, CA 95472800-998-9938 (in the United States or Canada)707-829-0515 (international or local)707-829-0104 (fax)We have a web page for this book, where we list errata, examples, and any additionalinformation. You can access this page at https://oreil.ly/NLPSpark.Email bookquestions@oreilly.com to comment or ask technical questions about thisbook.For news and information about our books and courses, visit http://oreilly.com.Find us on Facebook: http://facebook.com/oreillyFollow us on Twitter: http://twitter.com/oreillymediaWatch us on YouTube: http://youtube.com/oreillymediaxiv Preface
AcknowledgmentsI want to thank my editors at O’Reilly Nicole Taché and Gary O’Brien for their helpand support. I want to thank the tech reviewers who were of great help in restructur‐ing the book. I also want to thank Mike Loukides for his guidance in starting thisproject.I want to thank David Talby for all his mentorship. I want to thank Saif Addin,Maziyar Panahi and the rest of the John Snow Labs team for taking the initial designDavid and I had, and making it into a successful and widely used library. I also wantto thank Vishnu Vettrivel for his support and counsel during this project.Finally, I want to thank my family and friends for their patience and encouragement.Preface xv
PART IBasics
CHAPTER 1Getting StartedIntroductionThis book is about using Spark NLP to build natural language processing (NLP) appli‐cations. Spark NLP is an NLP library built on top of Apache Spark. In this book I’llcover how to use Spark NLP, as well as fundamental natural language processing top‐ics. Hopefully, at the end of this book you’ll have a new software tool for workingwith natural language and Spark NLP, as well as a suite of techniques and someunderstanding of why these techniques work.Let’s begin by talking about the structure of this book. In the first part, we’ll go overthe technologies and techniques we’ll be using with Spark NLP throughout this book.After that we’ll talk about the building blocks of NLP. Finally, we’ll talk about NLPapplications and systems.When working on an application that requires NLP, there are three perspectives youshould keep in mind: the software developer’s perspective, the linguist’s perspective,and the data scientist’s perspective. The software developer’s perspective focuses onwhat your application needs to do; this grounds the work in terms of the product youwant to create. The linguist’s perspective focuses on what it is in the data that youwant to extract. The data scientist’s perspective focuses on how you can extract theinformation you need from your data.Following is a more detailed overview of the book.Part I, Basics Chapter 1 covers setting up your environment so you can follow along with theexamples and exercises in the book.3
Chapter 2, Natural Language Basics is a survey of some of the linguistic conceptsthat help in understanding why NLP techniques work, and how to use NLP tech‐niques to get the information you need from language. Chapter 3, NLP on Apache Spark is an introduction to Apache Spark and, mostgermane, the Spark NLP library. Chapter 4, Deep Learning Basics is a survey of some of the deep learning conceptsthat we’ll be using in this book. This book is not a tutorial on deep learning, butwe’ll try and explain these techniques when necessary.Part II, Building Blocks Chapter 5, Processing Words covers the classic text-processing techniques. SinceNLP applications generally require a pipeline of transformations, understandingthe early steps well is a necessity. Chapter 6, Information Retrieval covers the basic concepts of search engines. Notonly is this a classic example of an application that uses text, but many NLP tech‐niques used in other kinds of applications ultimately come from informationretrieval. Chapter 7, Classification and Regression covers some well-established techniquesof using text features for classification and regression tasks. Chapter 8, Sequence Modeling with Keras introduces techniques used in modelingnatural language text data as sequences. Since natural language is a sequence,these techniques are fundamental. Chapter 9, Information Extraction shows how we can extract facts and relation‐ships from text. Chapter 10, Topic Modeling demonstrates techniques for finding topics in docu‐ments. Topic modeling is a great way to explore text. Chapter 11, Word Embeddings discusses one of the most popular modern techni‐ques for creating features from text.Part III, Applications Chapter 12, Sentiment Analysis and Emotion Detection covers some basic applica‐tions that require identifying the sentiment of a text’s author—for example,whether a movie review is positive or negative. Chapter 13, Building Knowledge Bases explores creating an ontology, a collectionof facts and relationships organized in a graph-like manner, from a corpus. Chapter 14, Search Engine goes deeper into what can be done to improve a searchengine. Improving is not just about improving the ranker; it’s also about facilitat‐ing the user with features like facets.4 Chapter 1: Getting Started
Chapter 15, Chatbot demonstrates how to create a chatbot—this is a fun andinteresting application. This kind of application is becoming more and morepopular. Chapter 16, Object Character Recognition introduces converting text stored asimages to text data. Not all texts are stored as text data. Handwriting and oldtexts are examples of texts we may receive as images. Sometimes, we also have todeal with nonhandwritten text stored in images like PDF images and scans ofprinted documents.Part IV, Building NLP Systems Chapter 17, Supporting Multiple Languages explores topics that an applicationcreator should consider when preparing to work with multiple languages. Chapter 18, Human Labeling covers ways to use humans to gather data abouttexts. Being able to efficiently use humans to augment data can make an other‐wise impossible project feasible. Chapter 19, Productionizing NLP Applications covers creating models, Spark NLPpipelines, and TensorFlow graphs, and publishing them for use in production;some of the performance concerns that developers should keep in mind whendesigning a system that uses text; and the quality and monitoring concerns thatare unique to NLP applications.Other ToolsIn addition to Spark NLP, Apache Spark, and TensorFlow, we’ll make use of a numberof other tools: Python is one of the most popular programming languages used in data science.Although Spark NLP is implemented in Scala, we will be demonstrating its usethrough Python. Anaconda is an open source distribution of Python (and R, which we are notusing). It is maintained by Anaconda, Inc., who also offer an enterprise platformand training courses. We’ll use the Anaconda package manager, conda, to createour environment. Jupyter Notebook is a tool for executing code in the browser. Jupyter Notebookalso allows you to write markdown and display visualizations all in the browser.In fact, this book was written as a Jupyter notebook before being converted to apublishable format. Jupyter Notebook is maintained by Project Jupyter, which is anonprofit dedicated to supporting interactive data-science tools. Docker is a tool for easily creating virtual machines, often referred to as contain‐ers. We’ll use Docker as an alternative installation tool to setting up Anaconda. Itis maintained by Docker, Inc.Other Tools 5
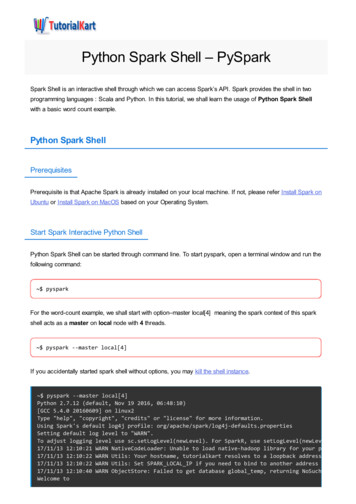
Setting Up Your EnvironmentIn this book, almost every chapter has exercises, so it is useful to make sure that theenvironment is working at the beginning. We’ll use Jupyter notebooks in this book,and the kernel we’ll use is the baseline Python 3.6 kernel. The instructions here useContinuum’s Anaconda to set up a Python virtual environment.You can also use the docker image for the necessary environment.These instructions were created from the set-up process for Ubuntu. There are addi‐tional set-up instructions online at the project’s GitHub page.Prerequisites1. Anaconda To set up Anaconda, follow the instructions.2. Apache Spark To set up Apache Spark, follow the instructions. Make sure that SPARK HOME is set to the location of your Apache Sparkinstallation.— If you are on Linux or macOS, you can put export SPARK HOME "/path/to/spark"— If you are on Windows, you can use System Properties to set an environ‐ment variable named SPARK HOME to "/path/to/spark" This was written on Apache Spark 2.4Optional: Set up a password for your Jupyter notebook server.Starting Apache Spark echo SPARK HOME/path/to/your/spark/installation spark-shellUsing Spark's default log4j profile: org/apache/spark/log4j-defaults.propertiesSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, usesetL ogLevel(newLevel).Spark context Web UI available at localhost:4040Spark context available as 'sc' (master local[*], app id .).Spark session available as 'spark'.Welcome to6 Chapter 1: Getting Started
/ / / /\ \/ \/ / / ' // / . /\ , / / / /\ \/ /version 2.3.2Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0102)Type in expressions to have them evaluated.Type :help for more information.scala Checking Out the Code1. Go to the GitHub repo for this project2. Check out the code, and run the following code examples in a terminal:a. Clone the repogit clone ok.gitb. Create the Anaconda environment—this will take a whileconda env create -f environment.ymlc. Activate the new environmentsource activate spark-nlp-bookd. Create the kernel for this environmentipython kernel install --user --name sparknlpbooke. Launch the notebook serverjupyter notebookf. Go to your notebook page at localhost:8888Getting Familiar with Apache SparkNow that we’re all set up, let’s start using Spark NLP! We will be using the 20 News‐groups Data Set from the University of California–Irvine Machine Learning Reposi‐tory. For this first example we use the mini newsgroups data set. Download the TARfile and extract it into the data folder for this project.Getting Familiar with Apache Spark 7
! ls ./data/mini omp.sys.ibm.pc.hardware tarting Apache Spark with Spark NLPThere are many ways we can use Apache Spark from Jupyter notebooks. We could usea specialized kernel, but I generally prefer using a simple kernel. Fortunately, SparkNLP gives us an easy way to start up.import sparknlpimport pysparkfrom pyspark import SparkConffrom pyspark.sql import SparkSessionfrom pyspark.sql import functions as funfrom pyspark.sql.types import *%matplotlib inlineimport matplotlib.pyplot as pltpackages ','.join(["JohnSnowLabs:spark-nlp:1.6.3",])spark conf SparkConf()spark conf spark conf.setAppName('spark-nlp-book-p1c1')spark conf spark conf.setAppName('master[*]')spark conf spark conf.set("spark.jars.packages", packages)spark SparkSession.builder.config(conf spark conf).getOrCreate()%matplotlib inlineimport matplotlib.pyplot as pltLoading and Viewing Data in Apache SparkLet’s look at how we can load data with Apache Spark and then at some ways we canview the data.import osmini newsgroups path os.path.join('data', 'mini newsgroups', '*')texts spark.sparkContext.wholeTextFiles(mini newsgroups path)schema StructType([StructField('filename', StringType()),StructField('text', StringType()),8 Chapter 1: Getting Started
])texts df spark.createDataFrame(texts, schema)texts df.show() -------------------- -------------------- filename text -------------------- -------------------- file:/home/alext/. Path: cantaloupe. file:/home/alext/. Newsgroups: sci.e. file:/home/alext/. Newsgroups: sci.e. file:/home/alext/. Newsgroups: sci.e. file:/home/alext/. Xref: cantaloupe. file:/home/alext/. Path: cantaloupe. file:/home/alext/. Xref: cantaloupe. file:/home/alext/. Newsgroups: sci.e. file:/home/alext/. Newsgroups: sci.e. file:/home/alext/. Xref: cantaloupe. file:/home/alext/. Path: cantaloupe. file:/home/alext/. Newsgroups: sci.e.
Spark NLP Learning to Understand Text at Scale. Alex Thomas Natural Language Processing with Spark NLP Learning to Understand Text at Scale Beijing Boston Farnham Sebastopol Tokyo. 978-1-492-04776-6 . A few years ago, I was working on a tutori