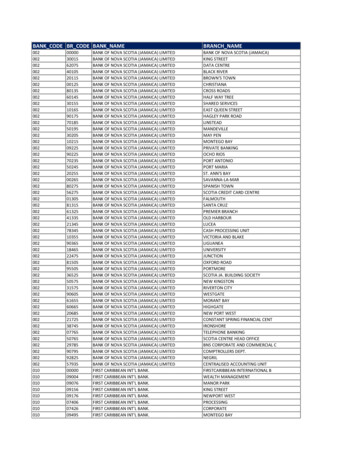
Transcription
ETL Interview Question BankAuthor: - Sheetal ShirkeVersion: - Version 0.1
ETL ArchitectureDiagram 1ETL Testing Questions1. What is Data WareHouse?Ans:A data warehouse (DW or DWH), also known as an enterprise data warehouse (EDW), is asystem used for reporting and data. DWs are central repositories of integrated data fromone or more disparate sources. They store current and historical data and are used forcreating analytical reports for knowledge workers throughout the enterprise (Refer Diagram1)2. Difference between Dataware House and Data Mart?Ans:Refer Diagram 1 Data mart and data warehousing are tools to assist management to come up withrelevant information about the organization at any point of time While data marts are limited for use of a department only, data warehousing appliesto an entire organization Data marts are easy to design and use while data warehousing is complex anddifficult to manage Data warehousing is more useful as it can come up with information from anydepartment3. What is ETL/Data Warehouse Testing?Ans:ETL stands for Extract Transformation and Load, It collect the different source data fromHeterogeneous System (DB), Transform the data into Data warehouse (Target)At the Time of Transformation, Data are first transform to Staging Table (temporary table)
Based on Business rules the data are mapped into target table, this process are manuallymapped / we configure using ETL Tool.ETL not transformed the Duplicate dataData Transformation process speed based on Source and Target Data ware HouseWe need to consider the OLAP(Online Analytic Processing) Structure .Data warehouse ModelSource data consist of (XML, Flat file ,Database.Excel Report.Dataware HouseWe need to set the validation at time of data transformation like ‘Avoid the ‘NULL’ values inthe table, validate the data type as using Tiny int instead of integer .etcBased on the user requirement, ETL process starts.4. Explain what are the ETL testing operations include?Ans: Verify whether the data is transforming correctly according to businessrequirementsVerify that the projected data is loaded into the data warehouse without anytruncation and data lossMake sure that ETL application reports invalid data and replaces with default valuesMake sure that data loads at expected time frame to improve scalability andperformance5. What are the various tools used in ETL.Ans: Cognos Decision StreamOracle Warehouse Builder/Oracle Data IntegratorBusiness Objects XISAS business warehouseSAS Enterprise ETL server6. What are staging area in ETL testing and its purpose?Ans:Staging area is place where you hold temporary tables on data warehouse server. Stagingtables are connected to work area or fact tables. We basically need staging area to hold thedata, and perform data cleansing and merging, before loading the data into warehouse.7. What is Primary, Foreign keys and difference among them?Ans:Primary Key: A primary key is a field or combination of fields that uniquely identify a recordin a table, so that an individual record can be located without confusion.Foreign Key: A foreign key (sometimes called a referencing key) is a key used to link twotables together. Typically you take the primary key field from one table and insert it into theother table where it becomes a foreign key (it remains a primary key in the original table).
8. What is Surrogate Key?Ans:Surrogate key is a substitution for the natural primary key.It is just a unique identifier or number for each row that can be used for the primary key tothe table. The only requirement for a surrogate primary key is that it is unique for each rowin the table.Data warehouses typically use a surrogate, (also known as artificial or identity key), key forthe dimension tables primary keys.9. What is Fact and Dimensions?Ans:Fact:Facts are the metrics that business users would use for making business decisions. Generally,facts are mere numbers. The facts cannot be used without their dimensionsDimension:Dimensions are those attributes that qualify facts. They give structure to the facts.Dimensions give different views of the facts.The facts & Dimension tables are linked by means of key called surrogate keys. Each facttable would have a column surrogate key that would have a corresponding key in thedimension tables.10.Types of Dimensions.Ans:Slowly Changing Dimensions:Attributes of a dimension that would undergo changes over time. It depends on the businessrequirement whether particular attribute history of changes should be preserved in the datawarehouse. This is called a Slowly Changing Attribute and a dimension containing such anattribute is called a Slowly Changing Dimension.Rapidly Changing Dimensions:A dimension attribute that changes frequently is a Rapidly Changing Attribute. If you don’tneed to track the changes, the Rapidly Changing Attribute is no problem, but if you do needto track the changes, using a standard Slowly Changing Dimension technique can result in ahuge inflation of the size of the dimension. One solution is to move the attribute to its owndimension, with a separate foreign key in the fact table. This new dimension is called aRapidly Changing Dimension.Junk Dimensions:A junk dimension is a single table with a combination of different and unrelated attributes toavoid having a large number of foreign keys in the fact table. Junk dimensions are oftencreated to manage the foreign keys created by Rapidly Changing Dimensions.
Inferred Dimensions:While loading fact records, a dimension record may not yet be ready. One solution is togenerate a surrogate key with Null for all the other attributes. This should technically becalled an inferred member, but is often called an inferred dimension.Conformed Dimensions:A Dimension that is used in multiple locations is called a conformed dimension. A conformeddimension may be used with multiple fact tables in a single database, or across multiple datamarts or data warehouses.Degenerate Dimensions:A degenerate dimension is when the dimension attribute is stored as part of fact table, andnot in a separate dimension table. These are essentially dimension keys for which there areno other attributes. In a data warehouse, these are often used as the result of a drill throughquery to analyze the source of an aggregated number in a report. You can use these valuesto trace back to transactions in the OLTP system.Role Playing Dimensions:A role-playing dimension is one where the same dimension key — along with its associatedattributes — can be joined to more than one foreign key in the fact table. For example, afact table may include foreign keys for both Ship Date and Delivery Date. But the same datedimension attributes apply to each foreign key, so you can join the same dimension table toboth foreign keys. Here the date dimension is taking multiple roles to map ship date as wellas delivery date, and hence the name of Role Playing dimension.Shrunken Dimensions:A shrunken dimension is a subset of another dimension. For example, the Orders fact tablemay include a foreign key for Product, but the Target fact table may include a foreign keyonly for Product Category, which is in the Product table, but much less granular. Creating asmaller dimension table, with Product Category as its primary key, is one way of dealing withthis situation of heterogeneous grain. If the Product dimension is snowflake, there isprobably already a separate table for Product Category, which can serve as the ShrunkenDimension.Static Dimensions:Static dimensions are not extracted from the original data source, but are created within thecontext of the data warehouse. A static dimension can be loaded manually — for examplewith Status codes — or it can be generated by a procedure, such as a Date or Timedimension.11.Types of Facts.Ans:Additive:Additive facts are facts that can be summed up through all of the dimensions in the facttable. A sales fact is a good example for additive fact.
Semi-Additive:Semi-additive facts are facts that can be summed up for some of the dimensions in the facttable, but not the others.Eg: Daily balances fact can be summed up through the customers dimension but not throughthe time dimension.Non-Additive:Non-additive facts are facts that cannot be summed up for any of the dimensions present inthe fact table.Eg: Facts which have percentages, ratios calculated.Factless Fact Table:In the real world, it is possible to have a fact table that contains no measures or facts. Thesetables are called “Factless Fact tables”.Eg: A fact table which has only product key and date key is a factless fact. There are nomeasures in this table. But still you can get the number products sold over a period of time.Based on the above classifications, fact tables are categorized into two:Cumulative:This type of fact table describes what has happened over a period of time. For example, thisfact table may describe the total sales by product by store by day. The facts for this type offact tables are mostly additive facts. The first example presented here is a cumulative facttable.Snapshot:This type of fact table describes the state of things in a particular instance of time, andusually includes more semi-additive and non-additive facts. The second example presentedhere is a snapshot fact table.12.What SCD (Slowly Changing Dimensions) and its types?Ans:Slowly Changing Dimensions (SCD) - dimensions that change slowly over time, rather than changingon regular schedule, time-base. In Data Warehouse there is a need to track changes in dimensionattributes in order to report historical data. In other words, implementing one of the SCD typesshould enable users assigning proper dimensions attribute value for given date? Example of suchdimensions could be: customer, geography, and employee.There are many approaches how to deal with SCD. The most popular are:Type 0 - The passive methodType 1 - Overwriting the old valueType 2 - Creating a new additional recordType 3 - Adding a new column
Type 4 - Using historical tableType 6 - Combine approaches of types 1, 2, 3 (1 2 3 6)Type 0 - The passive method. In this method no special action is performed upon dimensionalchanges. Some dimension data can remain the same as it was first time inserted, others may beoverwritten.Type 1 - Overwriting the old value. In this method no history of dimension changes is kept in thedatabase. The old dimension value is simply overwritten be the new one. This type is easy tomaintain and is often use for data which changes are caused by processing corrections (e.g. removalspecial characters, correcting spelling errors).Before the change:Customer ID Customer Name Customer Type1Cust 1CorporateAfter the change:Customer ID Customer Name Customer Type1Cust 1RetailType 2 - Creating a new additional record. In this methodology all history of dimension changes iskept in the database. You capture attribute change by adding a new row with a new surrogate keyto the dimension table. Both the prior and new rows contain as attributes the natural key (or otherdurable identifier). Also 'effective date' and 'current indicator' columns are used in this method.There could be only one record with current indicator set to 'Y'. For 'effective date' columns, i.e.start date and end date, the end date for current record usually is set to value 9999-12-31.Introducing changes to the dimensional model in type 2 could be very expensive databaseoperation so it is not recommended to use it in dimensions where a new attribute could be addedin the future.Before the change:Customer ID Customer Name Customer Type Start Date End Date Current Flag1Cust 1Corporate22-07-2010 31-12-9999 YAfter the change:Customer ID Customer Name Customer Type Start Date End Date Current Flag1Cust 1Corporate22-07-2010 17-05-2012 N2Cust 1Retail18-05-2012 31-12-9999 YType 3 - Adding a new column. In this type usually only the current and previous value of dimensionis kept in the database. The new value is loaded into 'current/new' column and the old one into'old/previous' column. Generally speaking the history is limited to the number of column createdfor storing historical data. This is the least commonly needed technique.
Before the change:Customer ID Customer Name Current Type Previous Type1Cust 1CorporateCorporateAfter the change:Customer ID Customer Name Current Type Previous Type1Cust 1RetailCorporateType 4 - Using historical table. In this method a separate historical table is used to track alldimensions attribute historical changes for each of the dimension. The 'main' dimension table keepsonly the current data e.g. customer and customer history tables.Current table:Customer ID Customer Name Customer Type1Cust 1CorporateHistorical table:Customer ID Customer Name Customer Type Start Date End Date1Cust 1Retail01-01-2010 21-07-20101Cust 1Other22-07-2010 17-05-20121Cust 1Corporate18-05-2012 31-12-9999Type 6 - Combine approaches of types 1, 2, 3 (1 2 3 6). In this type we have in dimension tablesuch additional columns as: current type - for keeping current value of the attribute. All history records for given itemof attribute have the same current value. historical type - for keeping historical value of the attribute. All history records for givenitem of attribute could have different values. start date - for keeping start date of 'effective date' of attribute's history. end date - for keeping end date of 'effective date' of attribute's history. current flag - for keeping information about the most recent record.In this method to capture attribute change we add a new record as in type 2. Thecurrent type information is overwritten with the new one as in type 1. We store the historyin a historical column as in type 3.Customer I Customer NamCurrent Type Historical Type Start Date End Date Current FlagDe1Cust 1CorporateRetail01-01201021-072010N2Cust 1CorporateOther22-07201017-052012N
3Cust 1CorporateCorporate18-05201231-129999Y13.What are OLTP and OLAP?Ans:OLTP
ETL Interview Question Bank Author: - Sheetal Shirke Version: - Version 0.1 . ETL Architecture Diagram 1 ETL Testing Questions 1. What is Data WareHouse? Ans: A data warehouse (DW or DWH), also known as an enterprise data warehouse (EDW), is a system used for reporting and data. DWs are central repositories of integrated data from one or more disparate sources. They store current and .