Transcription
“ALEXANDRU IOAN CUZA” UNIVERSITY OF IAȘIFACULTY OF COMPUTER SCIENCEDISSERTATION THESISIn-Memory Relational DatabaseSystemsproposed by-- Róbert Kristó--Session: July, 2016Scientific coordinatorAsist. Dr. Vasile Alaiba1
“ALEXANDRU IOAN CUZA” UNIVERSITY OF IAȘIFACULTY OF COMPUTER SCIENCEIn-Memory Relational DatabaseSystems-- Róbert Kristó --Session: July, 2016Scientific coordinatorAsist. Dr. Vasile Alaiba2
STATEMENT REGARDING ORIGINALITY AND COPYRIGHTI hereby declare that the dissertation thesis with the title In-Memory RelationalDatabase Systems is written by me and wasn’t submitted to another university or highereducation institution in the country or abroad. Also, I hereby declare that all the sources,including the ones retrieved online are appropriately cited in this paper, respecting therules of avoiding Copyright infringement:-all exactly reproduced excerpts, including translations from other languages, arewritten using quotes and hold an accurate reference to their source;-rephrased texts written by other authors hold an accurate reference to thesource;-the source code, images, etc. taken from open-source projects or other sourcesare used by respecting copyright ownership and hold accurate references;-summarizing ideas of other authors hold an accurate reference to the originaltext.Iași, dateGraduate: Róbert Kristó3
STATEMENT OF CONSENTI hereby declare that I agree that the dissertation thesis titled In-MemoryRelational Database Systems, the application source code and other content (graphics,multimedia, test data, etc.) presented in this paper can be used by the Faculty ofComputer Science.Also, I agree that the Faculty of Computer Science, “Alexandru Ioan Cuza”University of Iași can use, modify, reproduce and distribute the application, executableand source code, in non-commercial purposes, created by me for the current thesis.Iași, dateGraduate: Róbert Kristó4
Contents1. Abstract2. Introduction2.1. The Computation Problem2.2. RDBMS Terminology2.3. Relational Database Management Systems2.4. In-Memory Relational Database Management Systems2.5. The Durability of the In-Memory RDBMS3. OLTP vs OLAP3.1. Online Transaction Processing3.2. Online Analytical Processing3.3. Hybrid Transactional/Analytical Processing4. Row Store vs Column Store4.1. Row Store4.2. Column Store4.3. Row Store vs Column Store4.4. Row Stores and Column Stores in RDBMS5. RDBMS Indexes5.1. B Tree Indexes5.1. Bitmap Indexes5.1. Skip Lists5.1. Hash Indexes5.1. Column Store Indexes6. High Level Architecture of In-Memory RDBMS6.1. MemSQL6.2. VoltDB6.3. Oracle5
7. Experimental Test Case7.1. Test Case Description7.2. Test Case Setup7.3. Running the Queries7.4. Test Case Comparison8. Conclusions8.1. MemSQL Results8.2. VoltDB Results8.3. Oracle Results8.4. Final Conclusion8.5. Further Research9. Bibliography6
1. AbstractThis thesis wants to prove the advantage of using In-Memory relational databasemanagement systems in comparison with or alongside other classical relational databasemanagement systems which persists the information on the disk.It contains a short introduction about In-Memory databases, followed by some of thespecific technologies used by them. I will present the main differences between the row storeand column store ways of saving data, followed by the indexes used by these kind ofdatabases. After that the general high level architecture of some of the current vendors whichimplement In-Memory data stores.In the last chapter the reader will also see some experimental results done on theMemSQL, VoltDB, Oracle and NuoDB, followed by the thesis conclusion and furtherresearch proposal.7
2. IntroductionThe In-Memory relational database management systems have appeared after a largedrop in hardware prices and their sizes, the data access on the RAM being much faster incomparison with the one on the hard disk drive.2.1. The Computation ProblemUntil recently all the data processing was done overnight or weekends and the resultswere saved on the hard disk. These type of computing was performed in batches and couldtake from a few hours up to almost all weekend. This meant that the Database users had towork using all data from the previous day and also could not check how their changes wouldaffect the outcome until the next day. This meant that a lot of productivity was lost and alsocould potentially affect the overall revenue when the results were not the expected ones.Another issue with this old approach was that the results could not take in time inconsideration important events that occurred in that day.In the past few years the price of the RAM hardware became much cheaper whichmeans that now the most relevant data can be stored in RAM. In order to profit of these newprices most of the RDBMS (Relational Database Management Systems) started to provide anIn-Memory solution, and also other new In-Memory specialized new RDBMSs started toappear. This meant that the most user critical tables were now stored in RAM memory and thedata could be accessed much faster and also the calculation could be done faster.2.2. RDBMS TerminologyRelational database management systems, both the ones which store the records inmemory and the ones which store them on disk use a few specialized terms. A few of thewors from that vocabulary are presented below: Batch - it is a method of doing data processing in which operations are rangrouped together to finish a certain type of calculation Data Warehouse - it is one of the database management systems which storesold data in a denormalized form. It usually stores historical data which isprocessed in batches. It also contains old archive data CRUD Operations - CRUD (create, read, update, delete), represent the basicdatabase operations Query - it represents the operation of reading data from the database8
Primary Key - it assures us of the record uniqueness on a given column and itdoes not have null values (we can have a maximum of one primary key pertable) Unique Key - it is almost the same as the primary key, the difference being thatwe can have unique values and we can create more than one on a table Foreign Key - it makes the link between a record from the current table with arecord from another table using an unique key or primary key I/O - Input/Output represents the operations of reading and writing to disk Cache - this is where the most accessed data and recent data is saved on theRAM2.3. Relational Database Management SystemsThe first implementation of a Relational Database Management Systems was in 1974by IBM. It was called System R and it was only a prototype. The first commercial RelationalDatabase Management System was released in 1979 by Relational Software (now OracleCorporation) and it was called Oracle.The Relational Database Management Systems are based on the relational model thatwas invented by Edgar F. Codd. In these kind of databases the information is stored in tableswhich are connected with each other using relationships. The records in the tables are storedas tuple format.In these database systems the tables are linked together using relations (Foreign Keys).The tables are theoretically normalized using third normal form, but in practice they can bedenormalized in order to achieve better performance for corner case use cases. Almost all ofthe tables have a primary key which are used to uniquely identify records and have valuessaved for all the fields from the table.The RDBMS vendors usually provide the SQL language as a method to query thetables and also try to respect the SQL ANSI standard in order for the queries to be compatiblewith other vendors and to offer an easier transition for developers from one database toanother.2.4. In-Memory RDBMSIn order to better understand what are the In-Memory Relational DatabaseManagement Systems it must first be explained what they are not.Further most they are not In-Memory NoSQL (not only SQL) databases. Thesedatabases are not relational, most of them storing the data in a key-value store or document9
store type. One of the most popular database of this kind is Redis. It is indeed an In-Memorydatabase but it does not store the data in a relational way, as it uses a key-value storage. Itoffers isolation by using only one execution thread which is used by all the users in order.Another database type with whom it must not be confused are the classic databasesystems which are deployed as virtual machines directly in memory [7]. These can be ofcourse faster that being deployed on disk but they do not profit of the different memory type(RAM instead of hard disk). Another disadvantage of this kind of databases is that in case ofan outage the user can very easily lose all the information stored on them.These databases must also not be mistaken with distributed caching systems. Theseones save the most frequently accessed data in an application, and in case the user has enoughmachines at our disposal the user can save all the information from the database. This cachingmechanisms do not offer durability and this is why they are mostly not used to storeinformation which is crucial for the user.The principal characteristics of an In-Memory Relational Database ManagementSystem is that it offers a much faster access to the data thanks to the much lower latency ofthe RAM access in comparison with the one from the disk and it also uses specialized datastructures in order to have a faster access to the information. Because the information is saveddirectly in the RAM the user does not need a caching mechanism anymore, the exceptionbeing when the user save the data in dual mode (both on the hard drive and in the RAM), thisway the database may choose the faster way to access the data (it may use the cache when itchooses to access the data from the hard disc). As it will be presented in the next chapter, theIn-Memory Relationship Database Management Systems try to offer a hybrid system betweenOLTP and OLAP, being named HTAP or NEWSQL.2.5. The durability of the In-Memory RDBMSThe data being saved in the RAM, memory which is lost in case of an outage, thedurability becomes an important problem which needs to be solved. This can be solved byusing systems which have backups, which are made on longer periods of time, when thenumber of users is lower. These are used alongside with transaction logs which will beapplied on the backup in case of an outageAnother method used is by implementing a High-Available system, which consists inusing another machine in parallel (most of the time it is located in another location, called thedisaster recovery site) which continually gets instructions from the primary server and in casethe primary server has an outage a failover process will start making the secondary machinenow primary. The clients will automatically connect the newly assigned primary machine, this10
way the loss of information will be very small, the failover usually being done automaticallyand very fast.The durability can also be assured by some of the In-Memory RDBMS’s by saving thedata in dual format (both on disk and in memory), this way no information being lost in caseof a server restart as the data will still be saved on the hard disk.11
3. OLTP vs OLAPThe historical databases are split in two: OLTP and OLAP databases. In this chapter Iwill highlight the main differences of these two and the ways in which the In-MemoryRDBMS’s tries to unify them under only one system.3.1. Online Transaction ProcessingOnline transaction processing, most often abbreviated as OLTP, is the most used kindof database. The most important characteristics of the online transaction processing databasesare: contains real time data which comes from a lot of short and fast CRUD (create,read, update and delete) operations. uses simple queries which usually return or modify very few records most of the applications which are using this kind of databases must be able toprovide high user concurrency the schema is highly normalized and contains a lot of tables3.2. Online Analytical ProcessingOnline Analytical Processing, abbreviated as OLAP, represents the batch processingkind of databases. It is mostly used in data warehouse environments. The most typicalattributes of the Online Analytical Processing databases are: in usually helps in planning and decision making provides multi-dimensional views on consolidated historical data the data usually is consolidated from multiple online transaction processingsystem by periodic batches or from other user provided systems the queries are much more complex than the ones from the online transactionprocessing kind of systems and usually contain a lot of aggregations andinvolve a far larger number of records must provide timely answers to questions involving high resource usage is denormalized using a star/snowflake schema design3.2.1. Star SchemaThe Star Schema is mainly used in Data Warehouse systems. The star schema usuallyhas one or more fact tables which references a number of dimension tables.12
The fact tables contain transaction records with a transaction id and also ids which areforeign keys to the dimensional tables.The dimensional tables contain the actual information which needs to be accessed. Inthis way when the user is doing some computation the user only accesses records from thetables from which the user actually needs information, and by doing so the system is reducingthe I/O needed, which is the bottleneck in many database systems.3.2.2. Snowflake SchemaThe Snowflake schema resembles a lot to the Star Schema, the main differencebetween the two being that the Star schema contains only dimension directly linked to the facttables, while the Snowflake schema can contain dimension which are also linked betweenthem. A dimension can also be linked only to another dimension.3.3. Hybrid Transactional/Analytical ProcessingAs pointed above the two of them have very different use cases and historically thedata has been saved in both formats and usually in different systems. This meant a lot ofduplicated data being saved which until a few years ago meant a much higher expenses to thecustomers.As technology advanced and the hardware became much cheaper a new kind ofdatabase system started to be used called Hybrid Transactional/Analytical Processing(HTAP). This Relational Database Management System has both the capabilities of the OLTPand OLAP system. This new term has been created by Gartner, Inc., which is a firmspecialized in comparing products based on categories and placing them in four magicquadrants. It is used mainly by the In-Memory database systems.13
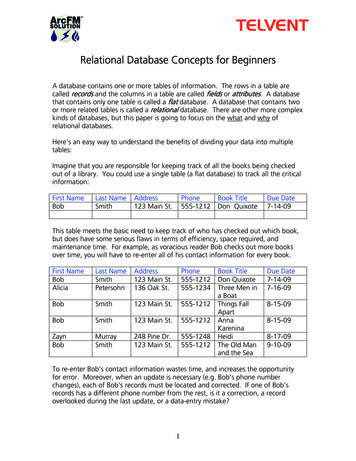
4. Row Store vs Column StoreCurrently the records in a RDBMS can be stored in row store and column storeformat.4.1. Row StoreIn the first database implementations the records have been saved in a row storeformat. This meant that for each records in the database a tuple was saved with values foreach field, they being saved next to each other and separated by a special character.An example of how the records are being saved is depicted bellow in Table 1.EMP NAMEJOBHIRE 50020Table 1 : Row Store Data SavingThe level row store format of the same records:1: SMITH, SALESMAN, 14/05/2015, 1000, 20 2: MACBETH, MANAGER, 13/01/2014, 1000, 25 3: MACBETH, SALESMAN, 20/06/2015, 1500, 20The first visible advantage is that a new record can be easily red, added, deleted orupdated as database can have a continuous read of the respective row id.A disadvantage is the fact that if the user only wants for example to read theEMP NAME and BONUS fields the user still has to read the whole record which means thata lot more I/O is needed which can greatly affect performance especially when a large numberof records is involved.14
4.2. Column StoreThe column store format is a new kind of saving the data which started to gainpopularity in RDBMS implementations only recently. In this format the user has separatelyeach column with the values of all the records from it.An example of how the records are saved in a column store format can be seen bellow,in Table 2.EMP IRE 00BONUS202520Table 2 - Column Store Data SavingAlso a high level column store format:SMITH: 1, MACBETH: 2, MACBETH: 3 SALESMAN: 1, MANAGER: 2, SALESMAN: 3 14/05/2015: 1, 13/01/2014: 2, 20/06/2015: 3 1000: 1, 1000: 2, 1500: 3 20: 1, 25: 2, 20: 3As it can be seen in the example above a few records are mentioned a few times. Inorder to improve the space used by the column store format and also improving the I/Ooperations needed the database can compress the values by the expense of CPU [10].15
A simple compression example is provided bellow:SMITH: 1, MACBETH: 2; 3 SALESMAN: 1; 3, MANAGER: 2 14/05/2015: 1, 13/01/2014: 2, 20/06/2015: 3 1000: 1; 2, 1500: 3 20: 1; 3, 25: 2The first visible advantage of the column store is that the database can now have lessI/O operations by reading only the data of interest. As an example if the user wants to readonly the data from the EMP NAME field the database does not need to also read the recordsfrom the other fields. A second advantage is as noted above the fact that the database can usecompression to reduce I/O operations and reduce consumed space.A disadvantage of using the column store format is that tuples might require multipleseeks.4.3. Row Store vs Column StoreIn conclusion column-oriented organizations are more efficient when aggregationoperation are being done over many rows but only if a smaller subset of fields are selected asthe number of data read is much smaller. Also the column store format are faster when manynew values are provided for a field at once in an update statement as only the values from onefield are accessed in order to change the data.The row-oriented organizations are more efficient when a bigger number of fields areaccessed at once from a record as the field values are next to each other and also if the recordis small enough a single database seek may be necessary. This is also true when a new recordis added to the database as.The advantages and disadvantages make the row store format to be well suited for anOLTP kind of application, while the column store format is best used in an OLAPenvironment.16
Number ofAttributes AccessedExecution Timein seconds forRow-StoreExecution Timein seconds forColumn-Store2257.462 sec128.731 sec3257.326 sec128.899 sec4259.526 sec153.923 sec9273.445 sec288.565 sec15280.778 sec8543.667 sec25290.199 sec20899.542 secTable 3 - PostgreSQL Row-Store vs Column-Store [12]A study on the PostgreSQL database has been made in order to compare the responsetime of the row store vs column store by comparing the number of columns selected in thequery. Also a plot was provided in the study:Figure 1- Column-Store vs Row-Store Performance in PostgreSQL [12]17
4.4. Row Store and Column Store in RDBMsEach RDBMS provider provides different implementation of these types of storages.Oracle Database 12c provides both row store and column store format, but row store only ondisk and column store is saved only on RAM. The same table is used, as in the records fromthe disk coincide with the ones on RAM. This improves a lot the read performance as theOracle Optimizer (a process which helps the database find the best execution plan in order toretrieve the records) can now choose to read the data from both the column store or row storedepending on the type of calculation. Oracle also provides different types of column storecompressing options. The two main compression types are Warehouse compression andArchive compression. Warehouse compression is ideal for query performance and isspecifically oriented towards scan-oriented queries which are mostly used in data warehouses.This is ideal for tables that are queried frequently as they occupy more space than usingarchive compression. The archive compression is in contrast better for tables which arequeried less frequently as they need more CPU in order to decompress the information butoccupy less space. A few of the algorithms used in order to compress the information are:Dictionary Encoding, Run Length Encoding, Bit-Packing, and the Oracle proprietarycompression technique called OZIP that offers extremely fast decompression that is tunedspecifically for Oracle Database.MemSQL also provides both row store and column store format, but instead it savesthe row store only on RAM and the column store only on disk. In this situation the tables arenot linked between them, meaning that it does not have to update the values in both locationsin case of an update, delete or insert operation, the only loss in this kind of situation being thatthe data from the in-memory storage can be lost in case of an outage if no high-availabilitysolution is in place.The best solution is provided by SAP HANA which provides all the combination, asin the row store can be saved both on disk and RAM and also the column store can be savedboth on disk and RAM. Also it has the option to choose if the tables are linked or not.Another good functionality provided by SAP HANA is that when it will do an insert into acolumn store format table it will have the option to initially save the new record in cache in arow store format in order to improve the overall insert performance as the record will beadded in the column store when the database will be less busy [4].18
5. RDBMS IndexesAn index is an auxiliary data structure which is used in order to faster access data fromthe tables. The cost of maintaining this extra structure is little in comparison with the readperformance gains. Usually the indexes contain some of the data from the table for which thesearch can be based and also a row identifier which acts like a pointer to the values from thetable, as the fastest way to access records from a table is by using the row id.The first indexes introduced in early RDBMs were the B Tree indexes. After theintroduction of the in-memory databases new lock free indexes have been invented which arealso lock free and are a better fit for RAM storage.5.1. B Tree IndexesThe B tree concept has first been introduced in the 1970s. The B tree is a balancedbinary tree which contains values only in the leaf nodes, the rest of the nodes being calleddecision nodes. Another important difference between the binary balanced tree is the fact thatwe have bidirectional pointers between the leaf nodes and that helps it greatly to scanconsecutive values or when the database wants to scan the whole index (the operation iscalled full index scan), as it does not also need to scan the decision nodes. The decision nodescontain a value which is used to compare with the searched value in order to find out if thevalue is saved on the left or right branch. The search performance gain is O(log 2 n).An example of B Tree index can be seen bellow:Figure 2 - B Tree [8]19
As it can be seen above to search the value 19 must be compared with only two othervalues. If the database wanted to search for the respective value directly in the table thedatabase would have had to compare it with 20 other values, and also the database wouldhave had to read the whole rows while searching if a row store column format was used.The main disadvantage is that it is not a lock free structure because after each update,insert or delete operation the database would need to rebalance the tree in order to retain theread performance.The B Tree indexes are useful only when the selectivity is high (if the number ofduplicates is around 10% or more the query will be faster accessing directly the table) orwhen all the needed fields are found inside the index.This index is good at searching for unique values and also to search for a range ofvalue as the records stored are in consecutive order.5.2. Bitmap IndexesThe bitmap indexes have also been introduced early in most of the RDBMs. Theyhave been first invented in 1985 and they are best used when the number of distinct values isvery low.An example of a bitmap index when storing cardinalities:Figure 3 - Bitmap Index [16]As it can be seen above when the search was made for example for the Cardinality therows which contain the value can be easily be found by accessing the row North (the cellswhich have a dot inside them contain the value).The bitmap index can be easily updated but in practice is not used very often as thereare not a lot of searches done on fields with low selectivity and also for example OracleDatabase provides bitmap indexes only in its Enterprise Edition.5.3. Skip ListsThis type of index was introduced in the year 1990, with almost 20 years after the wellknown B Tree Index. Unlike the B Tree Index this one does not guarantee a number ofsteps to find the results. It relies on probabilities, but the changes to not return a result in a20
satisfying time is very low, in average having a performance comparable with the one of a B Tree Index. This type of index fits well with the In-Memory database architecture because itcan profit of the RAM hardware type. Another big advantage of this type of index is thatunlike its B Tree Index counterpart it does not block resources, as it does not need to berebalanced like the B Tree. However if the user sees that the performance of the Skip lists isdegrading the user can rebuild it in order to have the data better scattered.Depending on the number of records the user has in the table the database can buildthis index using a number of lanes, representing the index depth. After the number of lanes isestablished by the DBMS it will start to do the inserts. The first records will be added andafter that it will do a “coin toss” in order to establish the level on which the record will beplaced. It will start with the lowest level and will use the “coin toss” technique on each leveluntil the coin toss result will return a negative result. Depending on each DBMSimplementation the database can have on each higher level a higher change of having anegative result in order to have the Skip List well balanced. This step represented theprobabilistic stage in order to determine the level on which each record will be placed. Inorder to add the rest of the records the database will also start from left to right and willdescend after until the database will find the values searched in the index of when thedatabase will get to the first level. The most left side will be considered as minus infinite andthe right side as plus infinite. This way when database start from the left (as our value ifbigger than minus infinite) database will compare our value with each of the values from thetowers from that level until database find one which is bigger than our value (or equal). In thatmoment database will go one level lower and database will make the same steps as the onesfrom the above level until database find our searched value or database get to the first level. Incase our searched value is already in the index database will add it to the list of the tower inwhich database found it or database will add a new tower in case it did not already exist, inwhich case database will restart the previously shown coin toss technique in order todetermine the tower’s height.As database can see in the above example database will simply add a new towerbetween other two, for which there is no need to block the whole index, this way concurrentusers can still use the Skip List.When database will search for a value in this index database will use a relatedtechnique to the one used at insert by doing a left to right and top to bottom search untildatabase will find a tower which has the searched value or until database finish searching theindex. In case database will find the searched value database will return all the records savedin that tower.21
A search example is given bellow, in Figure 4.Figure 4 - Skip List Search [9]In case the database wants to delete records the database will use the same techniqueas the one from the search, the only difference being that the database will delete the towerafter the database find it. Like in the case of the insert the database does not need to block thewhole index, the RDBMS simply deleting the searched tower.This type of index is implemented by the In-Memory RDBMS MemSQL, being therecommended user by this database vender. This type of index has a good performance atboth unique value searching and range searching as all the values in the Skip List are placedin consecutive order.5.4. Hash IndexThis type of index has been implemented by both classic RDBMSs like SQL Serverand new RDBMS competitors like MemSQL. This type of index has a good performance onlywhen the database is doing an unique value search and it has a very bad performance whenthe database are doing a range scan, and for this reason some of the RDBMS vendors allowthe customers to only create the index on primary or unique keys. The records of the index arestored in buckets which contain a number of different values. When a new value is inserted anew bucket will be created in which the database will store it unless the hash function returnsthe value of an already existing bucket. When a search will be made a hash function will beapplied to the searched value and after the database establish in which bucket its saved thedatabase will search for the record there (it is possible that the returned hash value exists butthe record does not exist in that bucket) [17].22
5.5. Column Store IndexesDifferent DBMS vendors made their proprietary indexes to help for a faster search ofdata. An index of this type was implemented by the Oracle Database in order to help us searchfor records in its In-Memory column store or in is Exadata column store.5.5.1. Column Store Indexes used by Oracle DatabaseAs it was pres
This thesis wants to prove the advantage of using In-Memory relational database management systems in comparison with or alongside other classical relational database management systems which persists the information on the disk. . It is indeed an In-Memory database but it does not store the data in a relational way, as it uses a key-value .